I am an Assistant Professor in the Department of Machine Learning at the University of North Carolina at Charlotte. My research focuses on video representation learning and robotic vision. I am also a co-founder of the Charlotte Vision Lab.
Building multimodal AI and robotics systems that learn from everyday human behavior to enable the next generation of assistive home robots.
I develop AI systems that learn from unstructured daily-life videos and multimodal sensory data to understand human activities, predict future actions, and enable intelligent robotic assistance. My research combines video foundation models, multimodal representation learning, vision-language-action (VLA) models, world models, and scalable self-supervised learning to transform real-world observations into actionable knowledge for AI agents and robots.
News2026
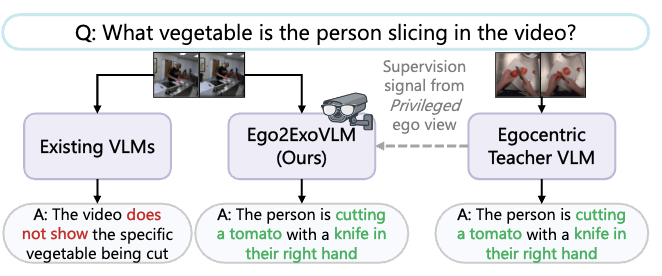
Jun: 4 papers accepted to ECCV 2026: VisCoP, Ego2Exo VLM, 3D FaceShell, and DnA.
May: Outstanding Reviewer for CVPR 2026 and Serving as Area Chair for BMVC 2026.
Mar: Serving as Area Chair for NeurIPS 2026 and Participation & Broadening Chair for WACV 2027.
Feb: 1 paper accepted to CVPR 2026 main (MS-Temba) and one to CVPR Findings (TICON).
Feb: Joined Editorial Board of Pattern Recognition as an Associate Editor.
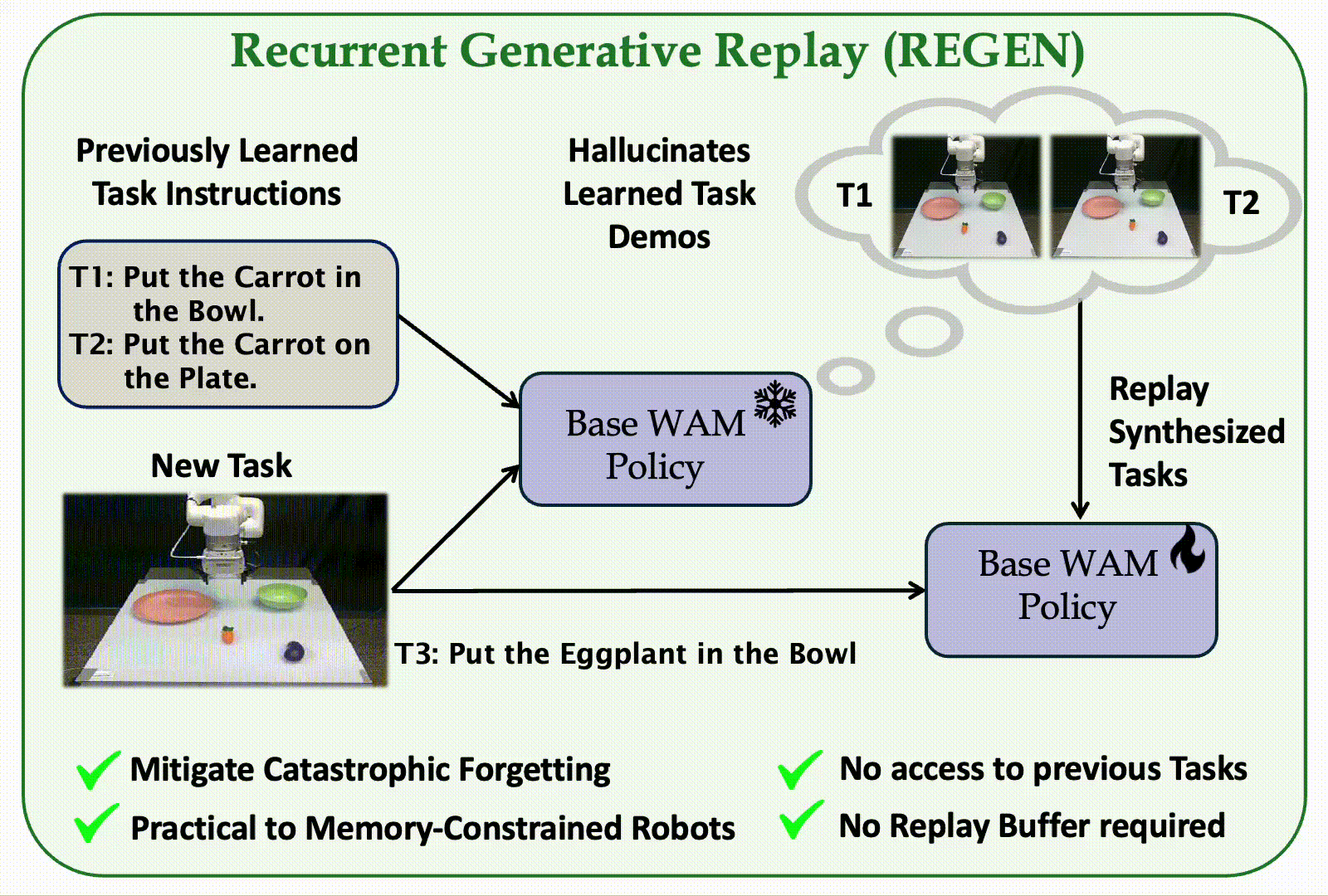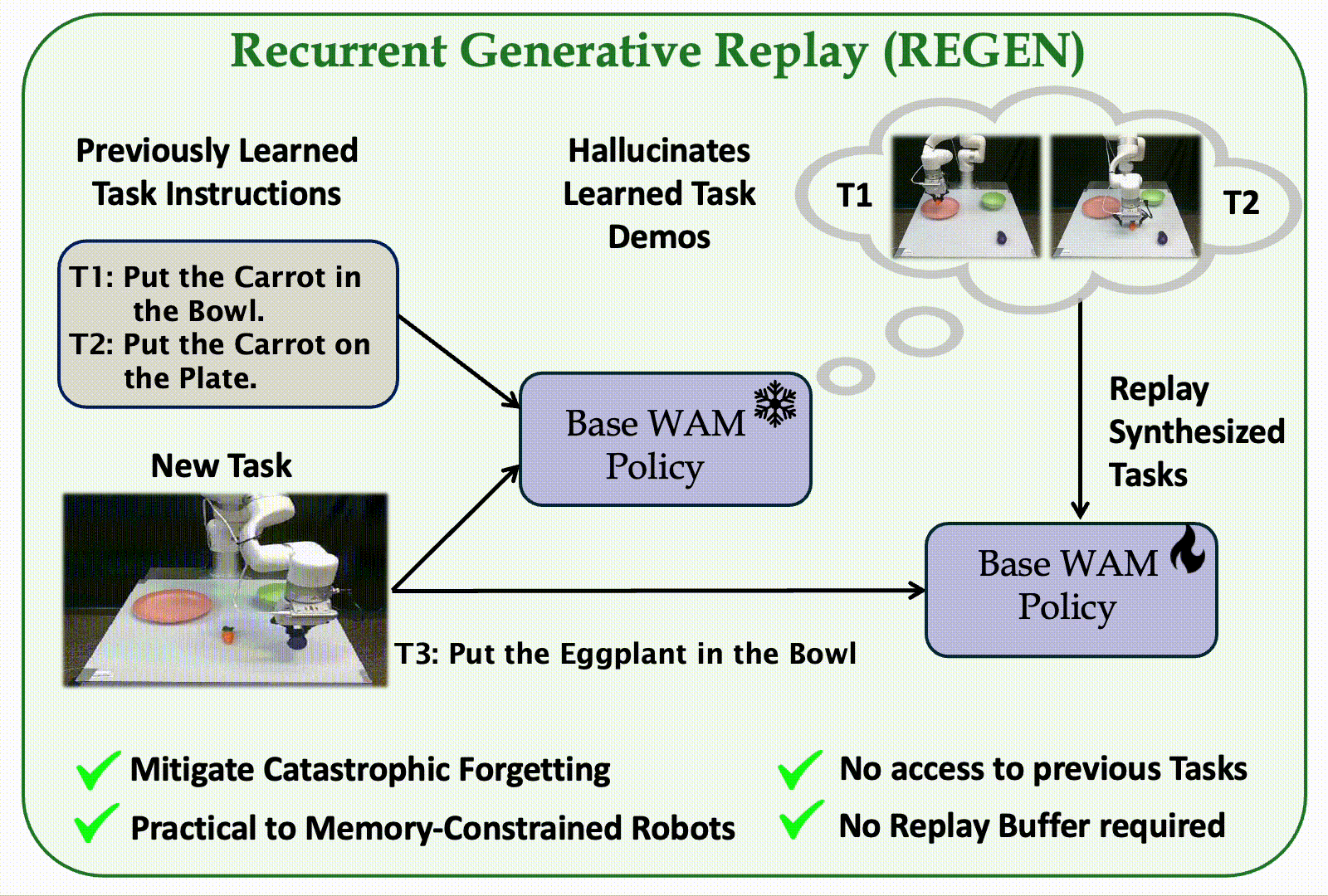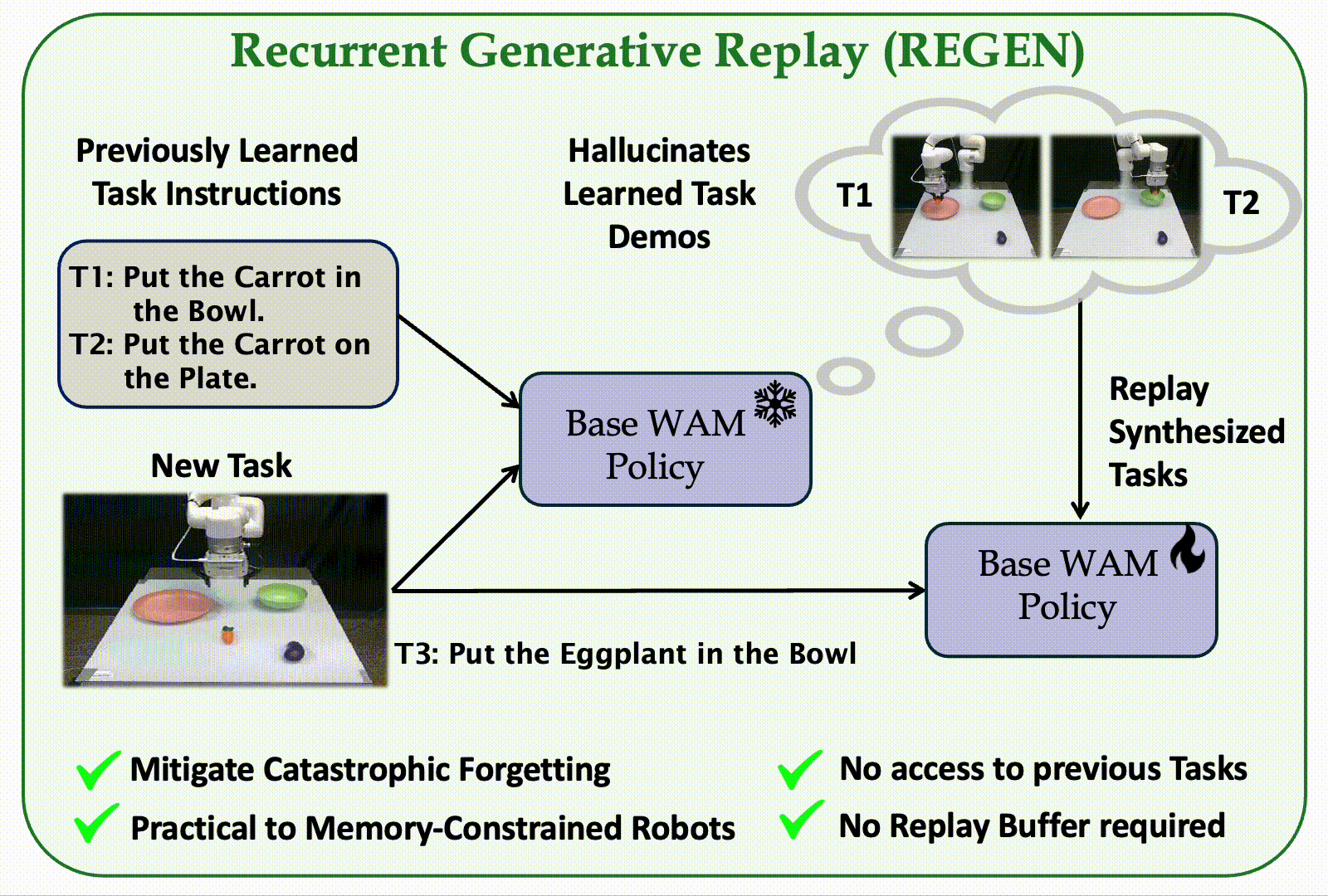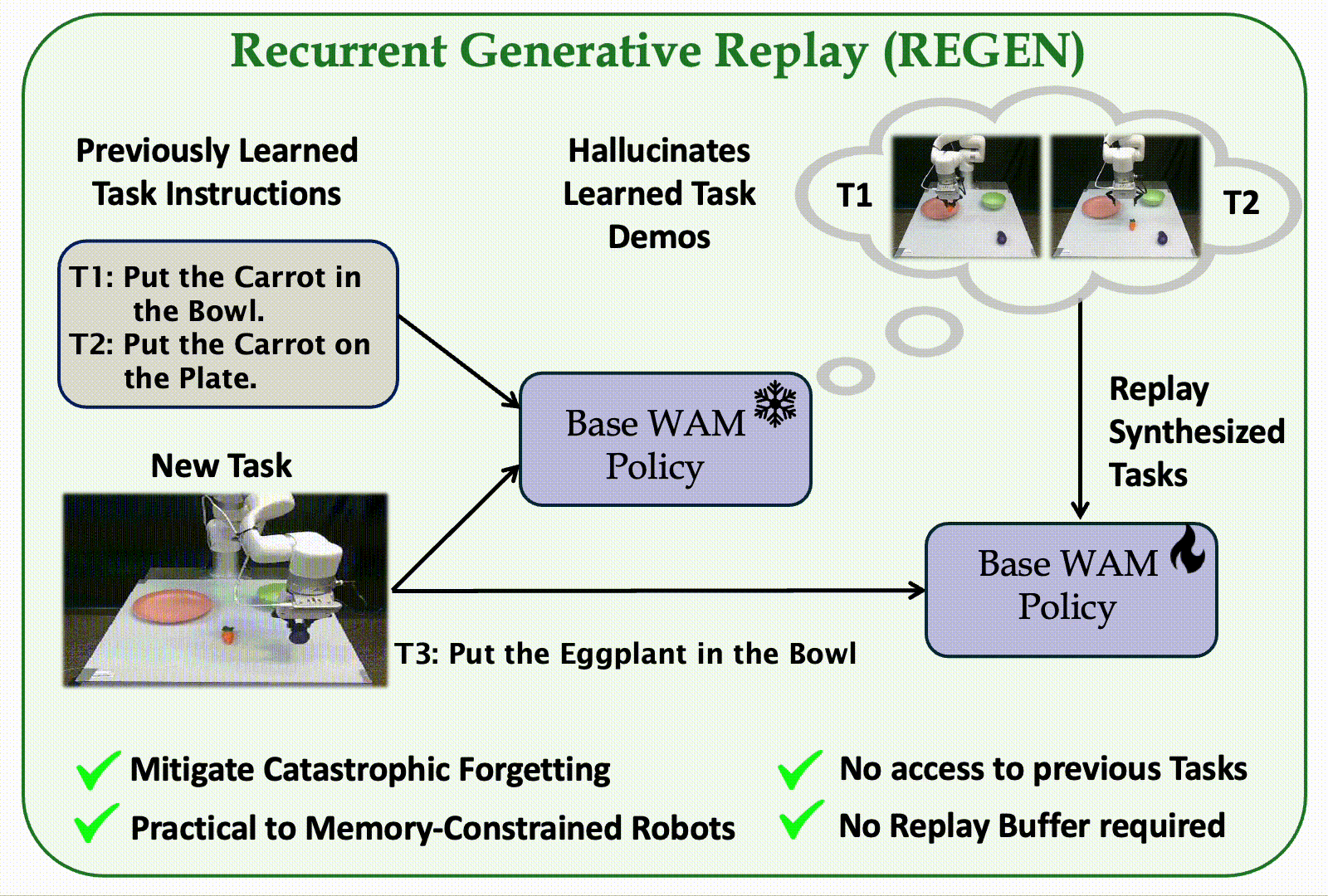
The first replay-based continual imitation learning framework that leverages the generative capabilities of World Action Models to synthesize replay trajectories without storing real demonstrations from previous tasks.
TIMEPROVE is a hybrid long-video reasoning framework that generates action-grounded hypotheses efficiently and verifies only sparse RGB evidence using an expensive VLM.
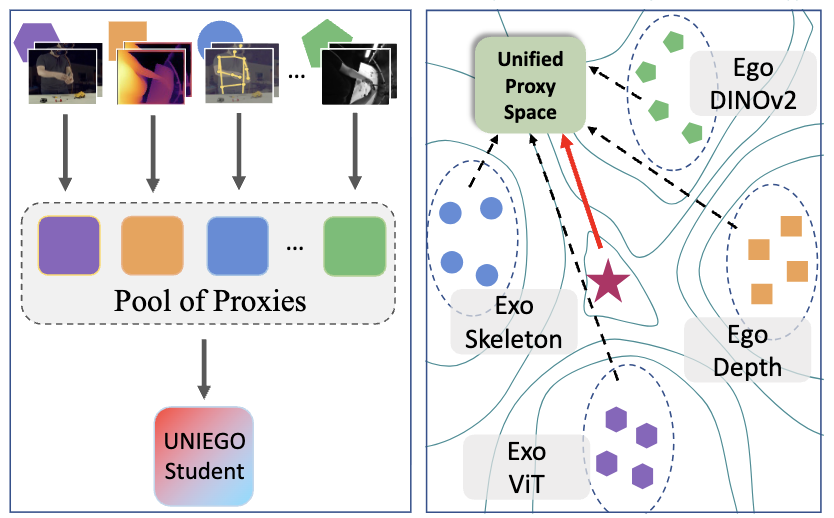
UNIEGO is a unified egocentric encoder trained via hierarchical distillation across ego-exo viewpoints, modalities, and foundation models, using representation-specific proxies as structured mediators.
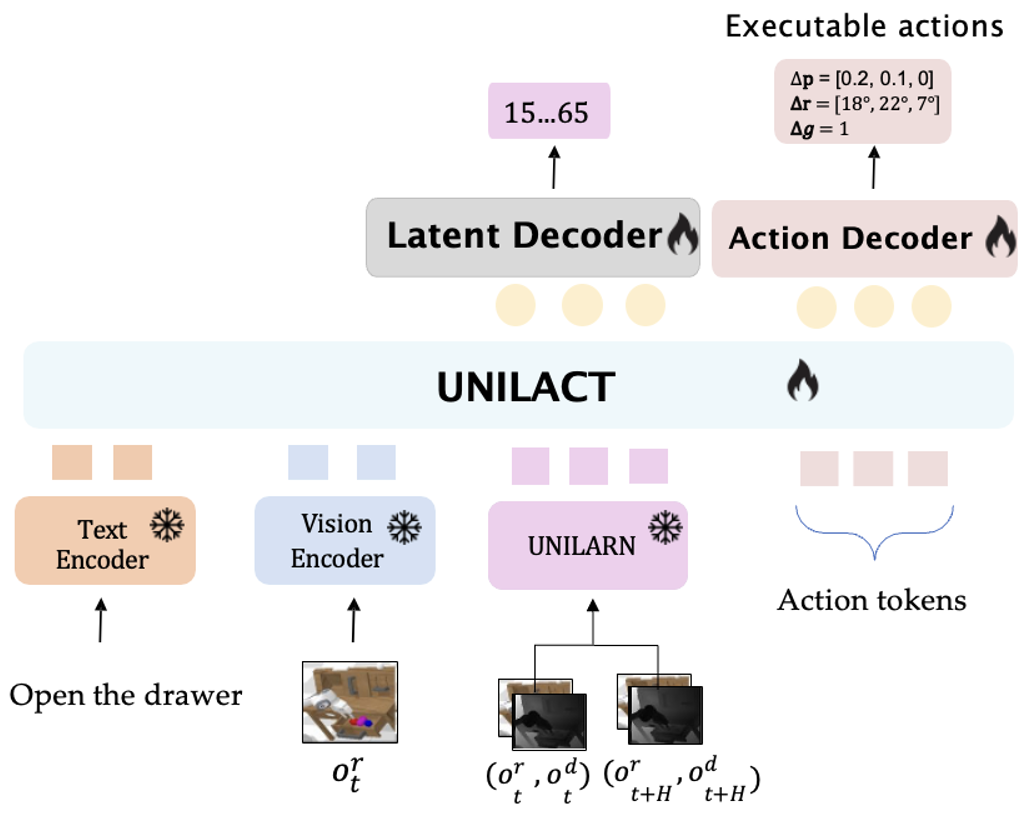
UniLACT is a Vision-Language-Action model that incorporates geometric structure through depth-aware latent pretraining, enabling downstream robot policies to inherit stronger spatial priors.
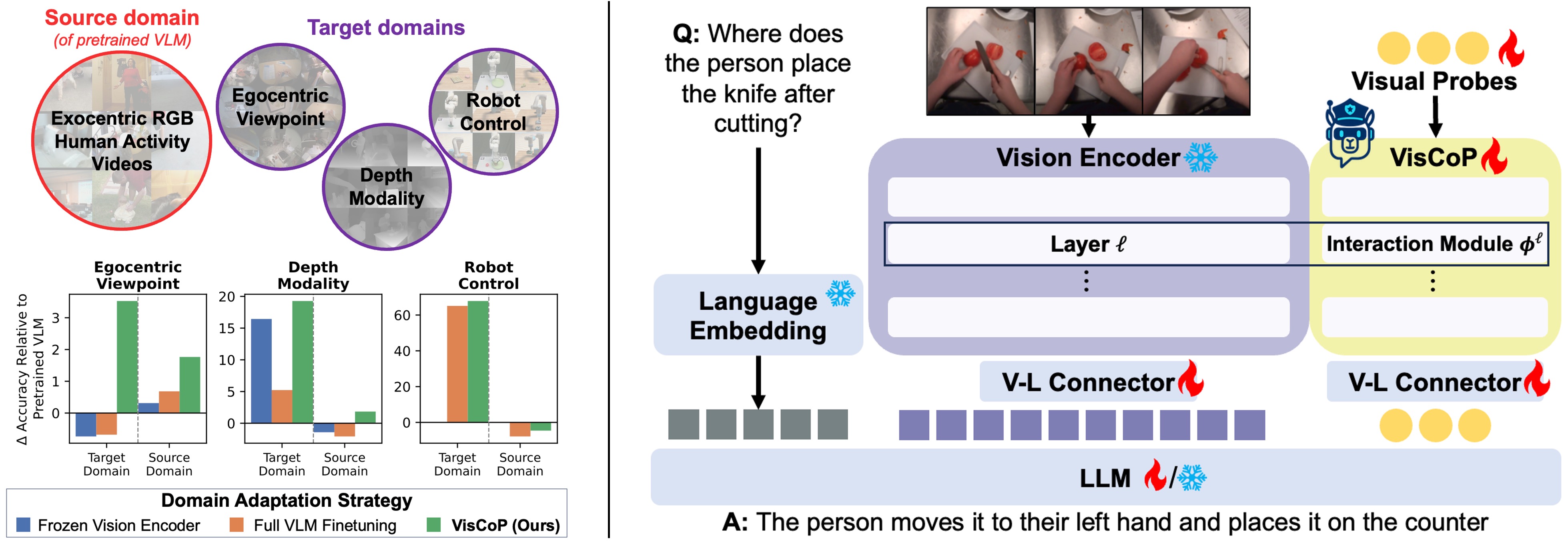
We introduce Vision Contextualized Probing (VisCoP), which augments the VLM's vision encoder with a compact set of learnable visual probes that enables efficient domain-specific adaptation with minimal modification to pretrained parameters.
3D FaceShell is a privacy-preserving framework that manipulates how vision-language models interpret 3D face avatars while preserving facial identity and visual realism.
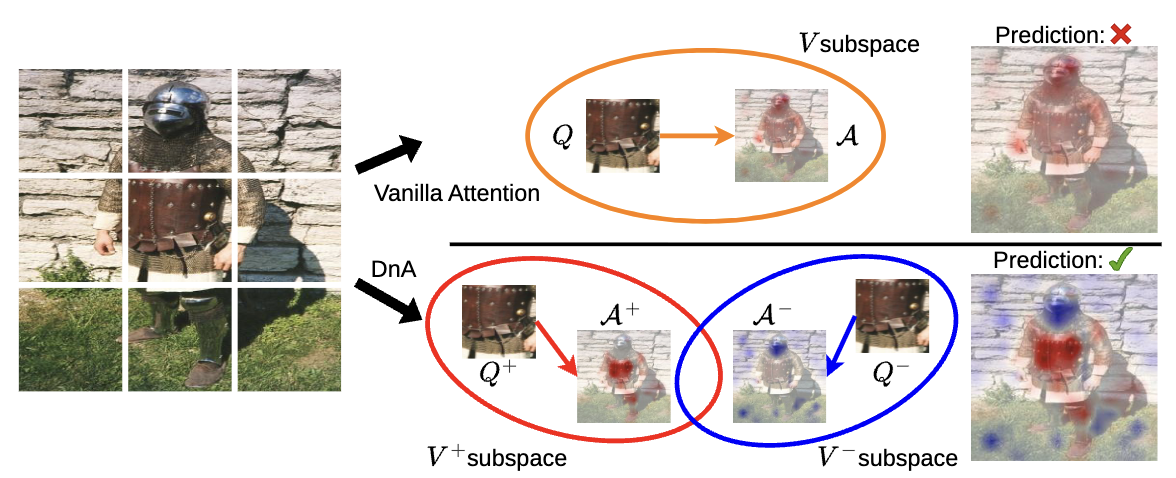
DnA introduces denoising attention to improve discriminability in visual tasks by separating relevant and irrelevant features into distinct interacting subspaces.
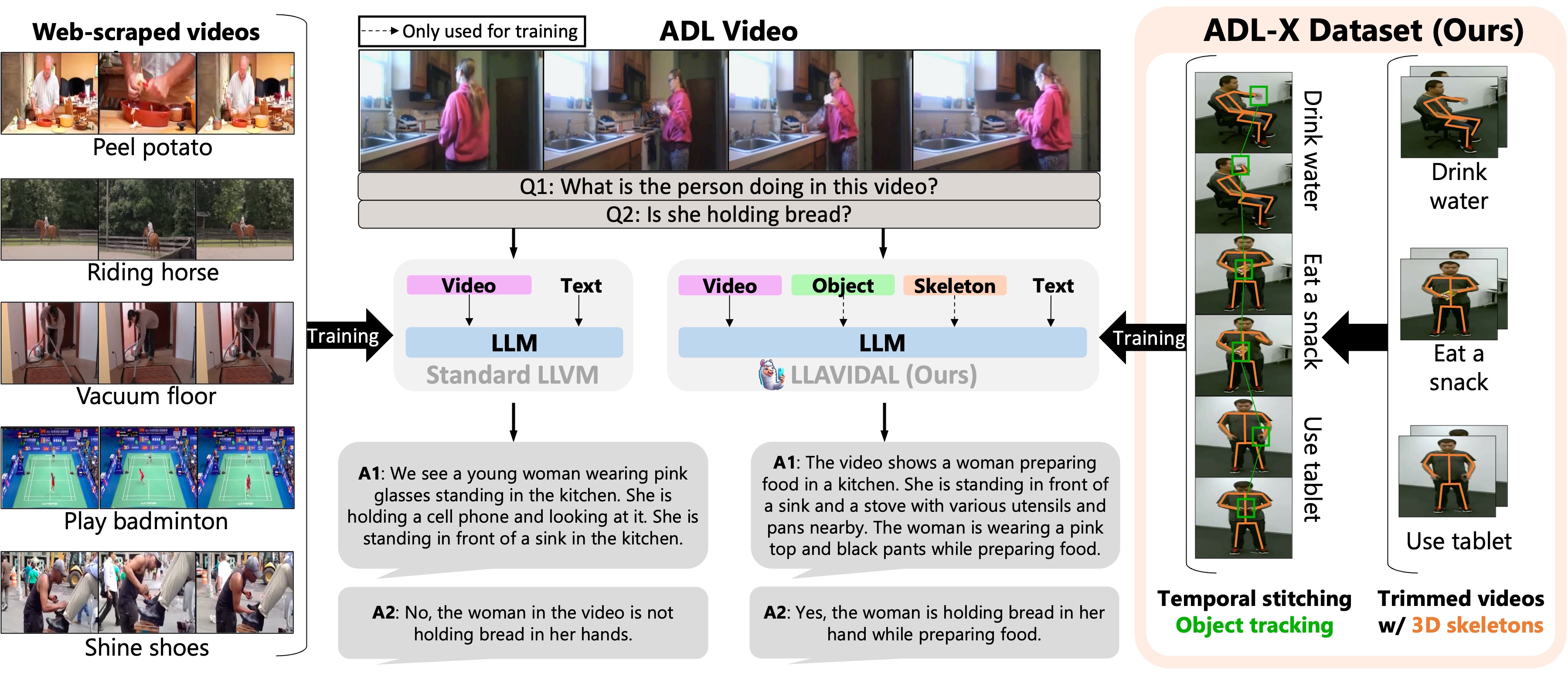
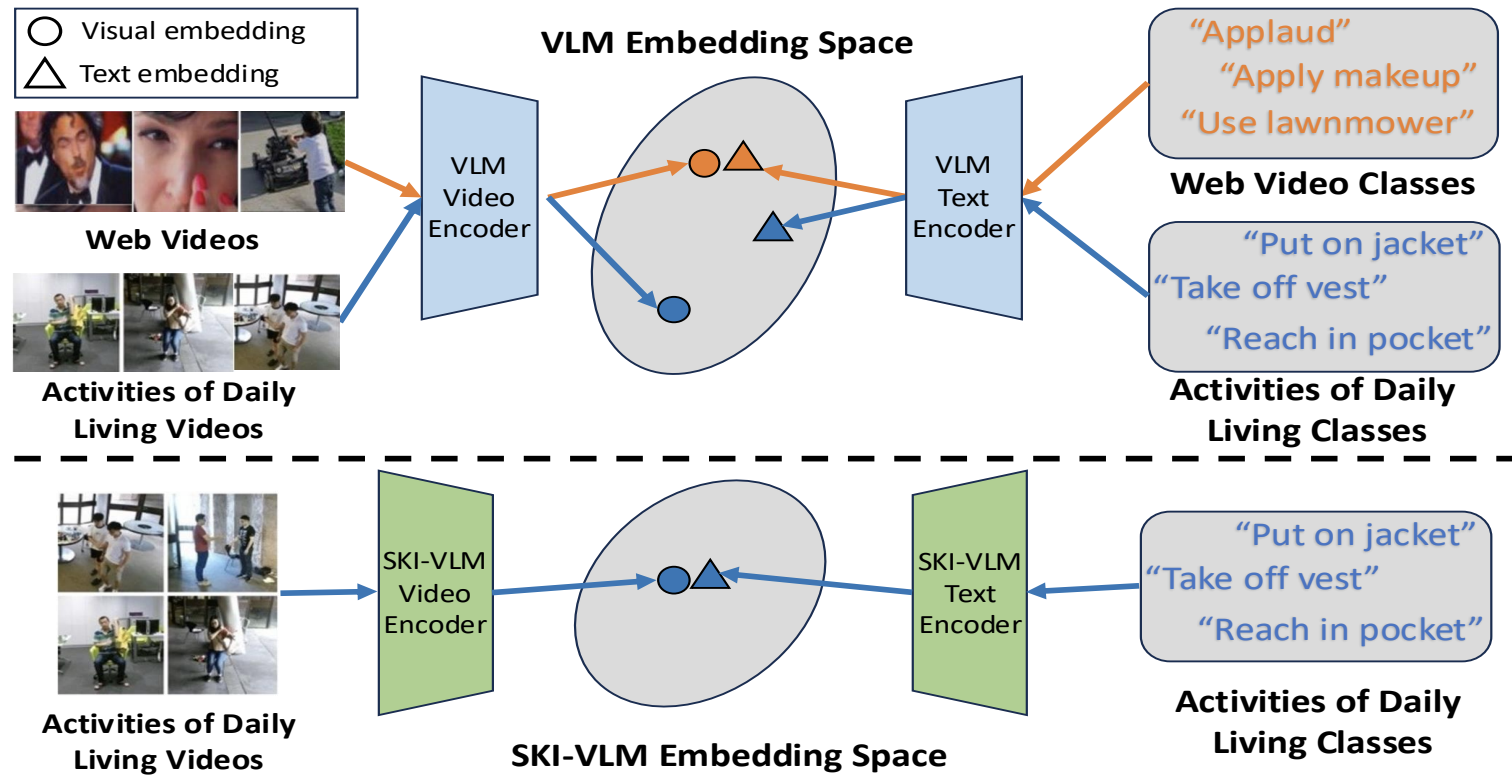
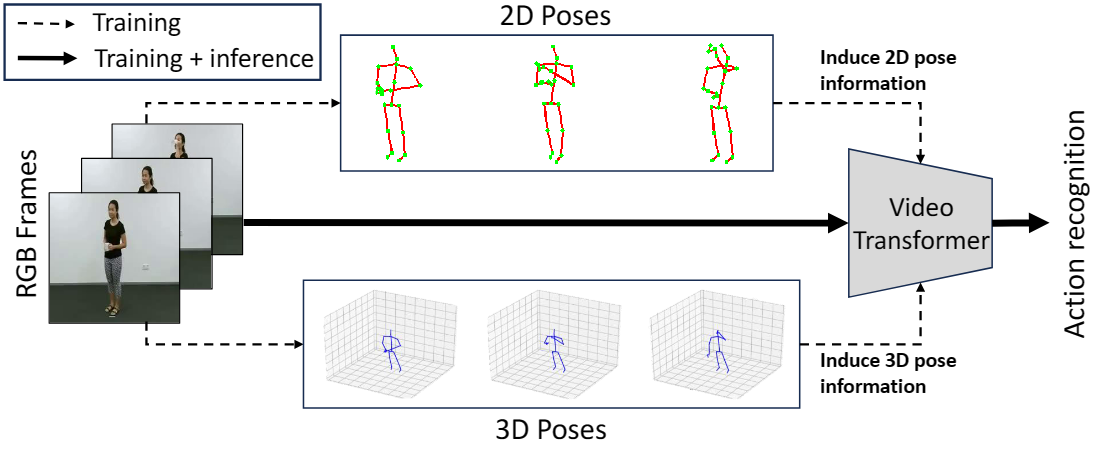
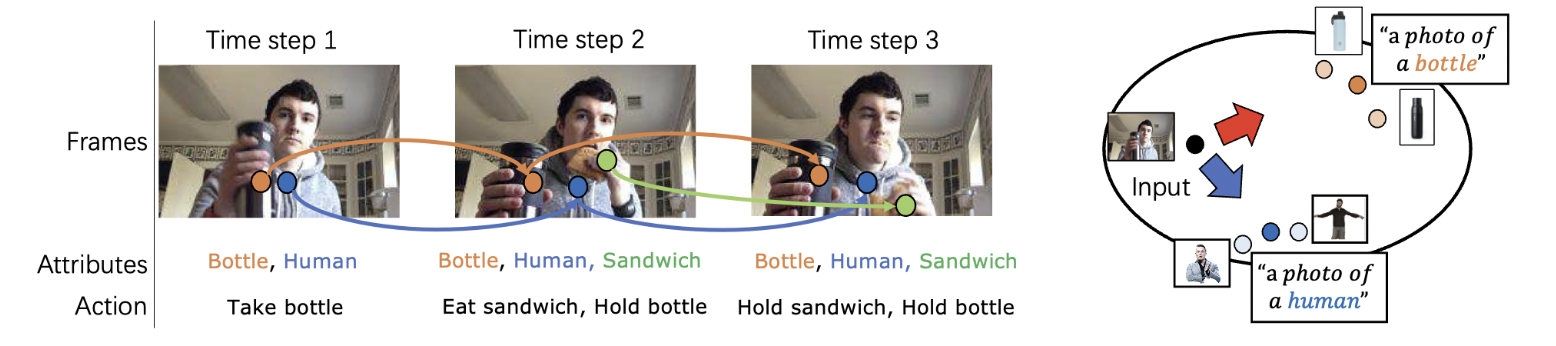
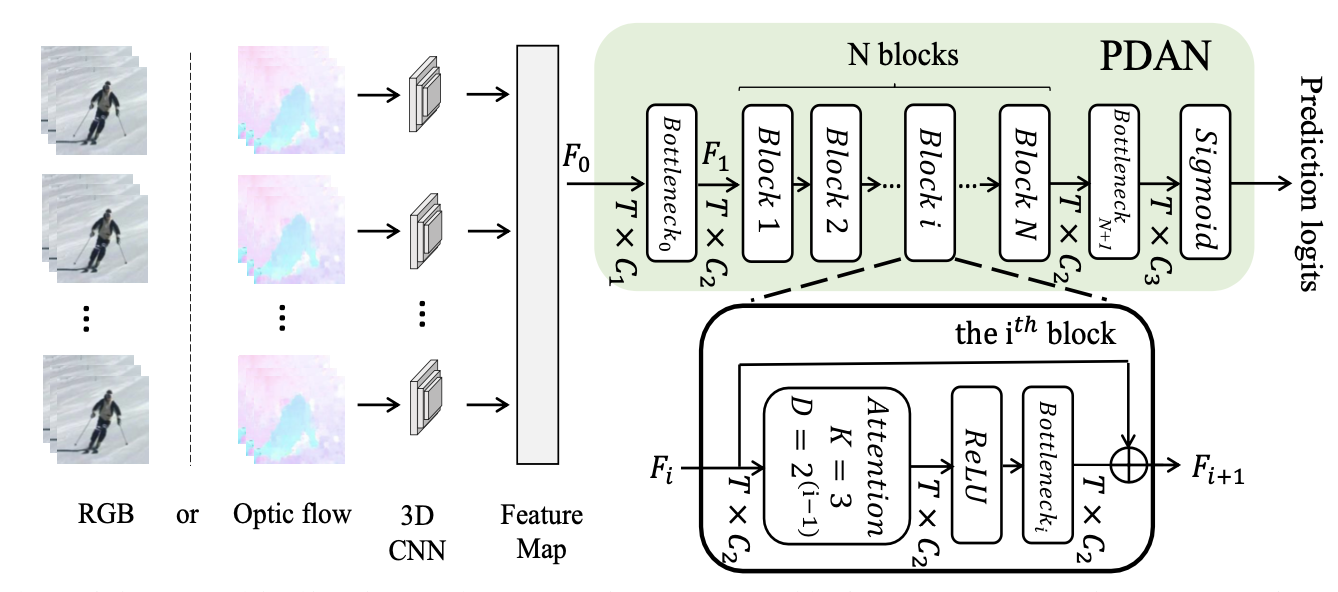
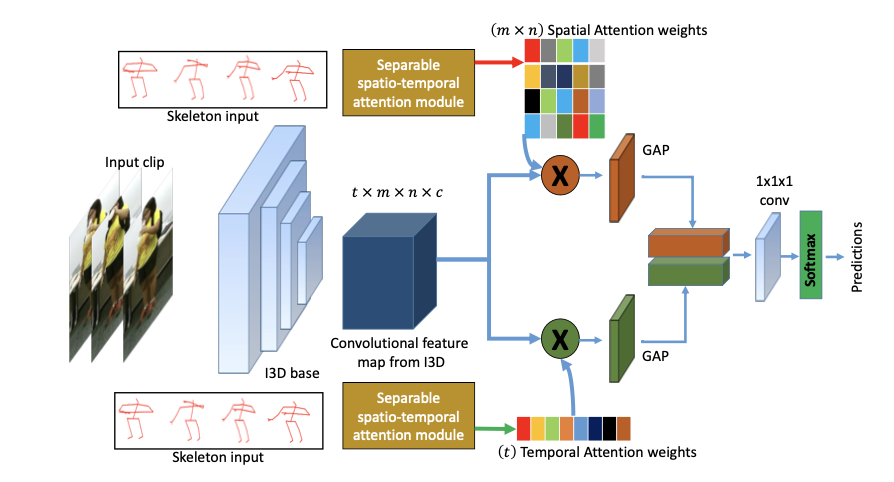
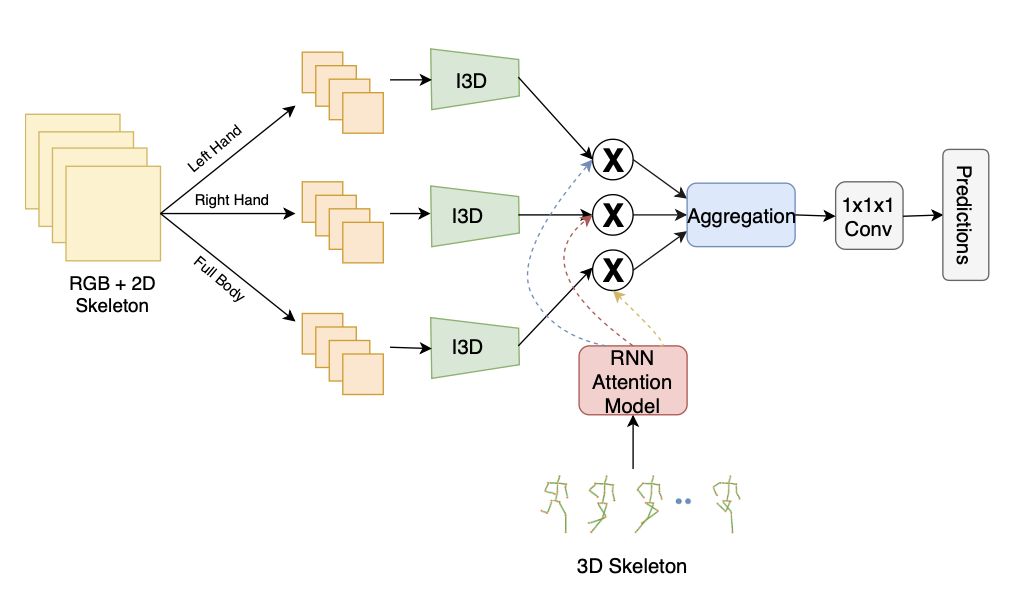
LLAVIDAL, a Large Language Vision Model, incorporates 3D poses and relevant object trajectories to understand the intricate spatiotemporal relationships within ADLs.
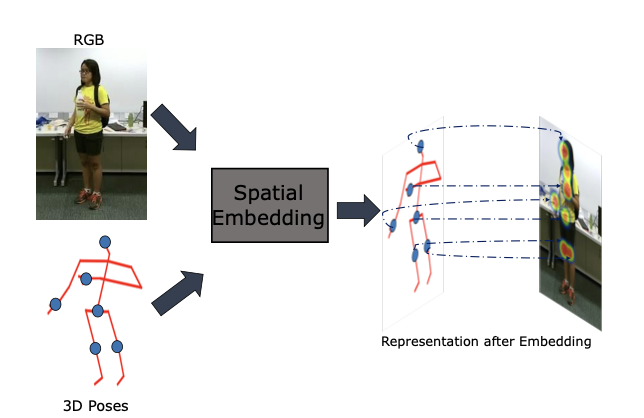
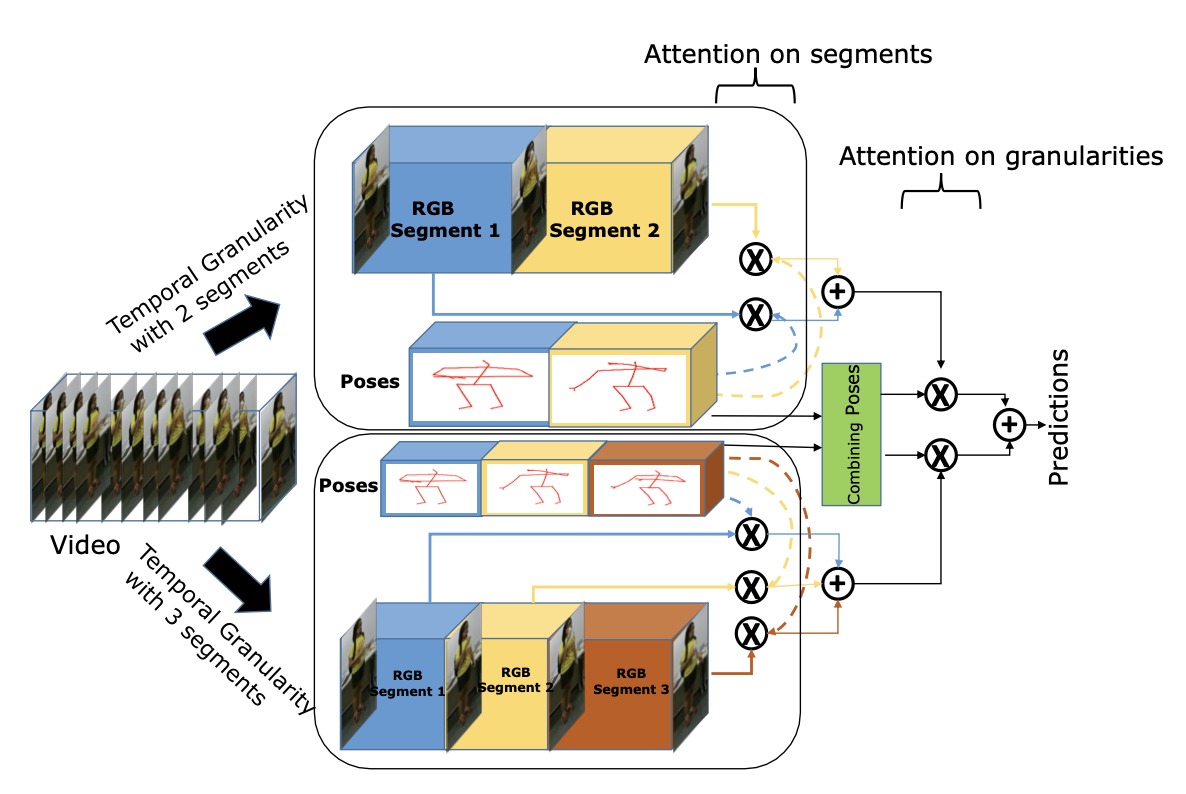
We introduce the first Pose Induced Video Transformer: PI-ViT (or π-ViT), a novel approach that augments the RGB representations learned by video transformers with 2D and 3D pose information.
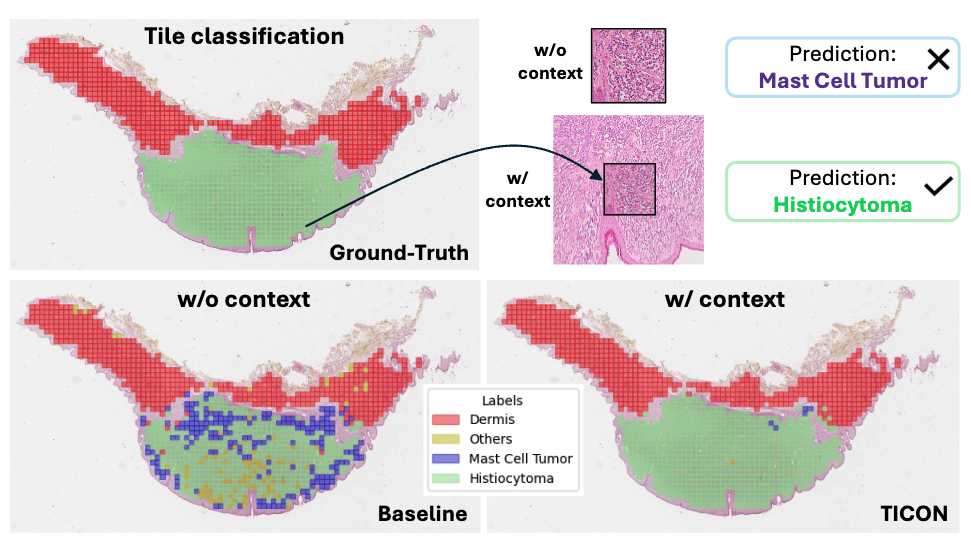
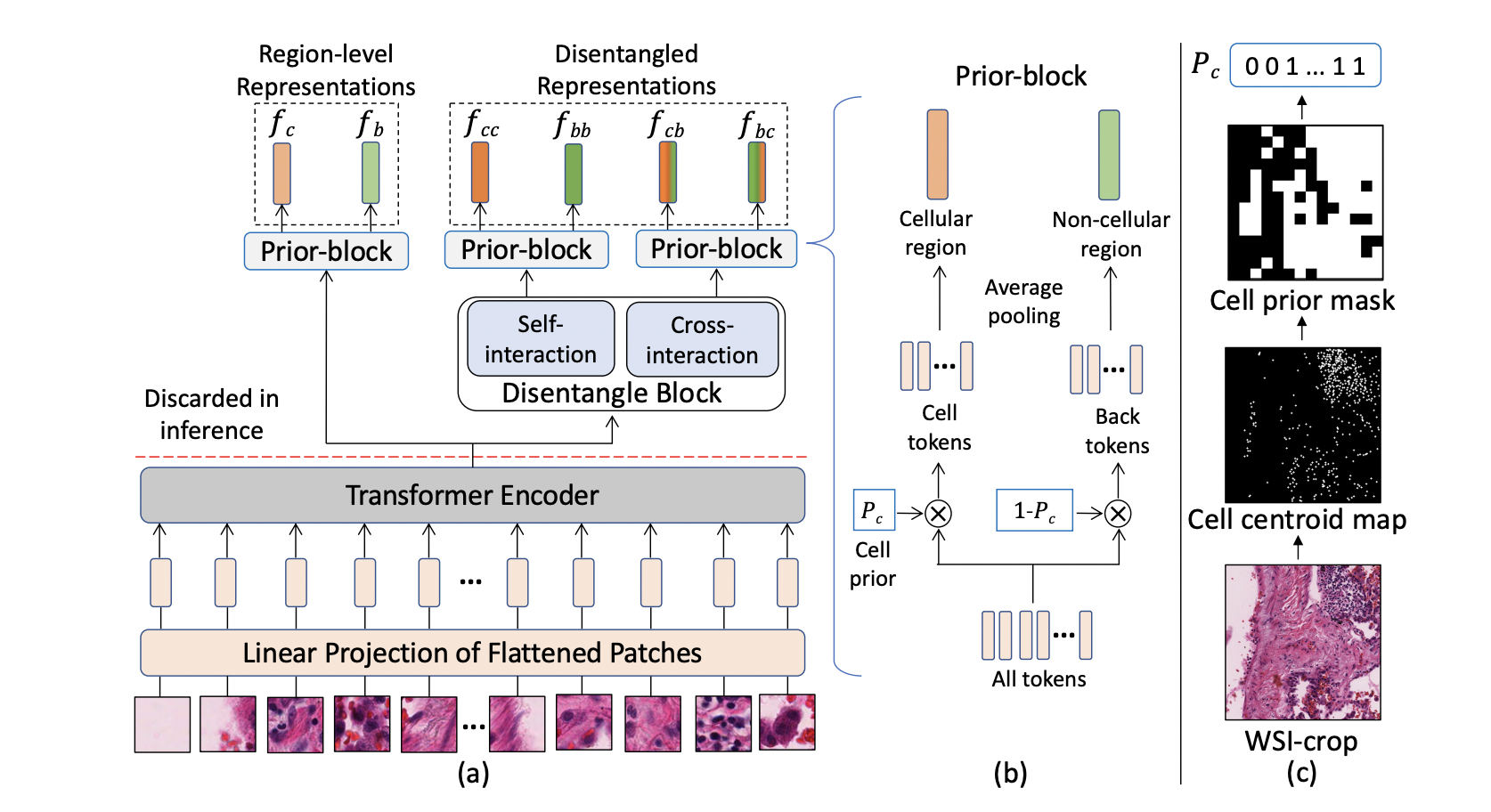
Self-Interpretable MIL (SI-MIL), the first interpretable-by-design MIL method for gigapixel WSIs, which provides de novo feature-level interpretations grounded on pathological insights for a WSI.
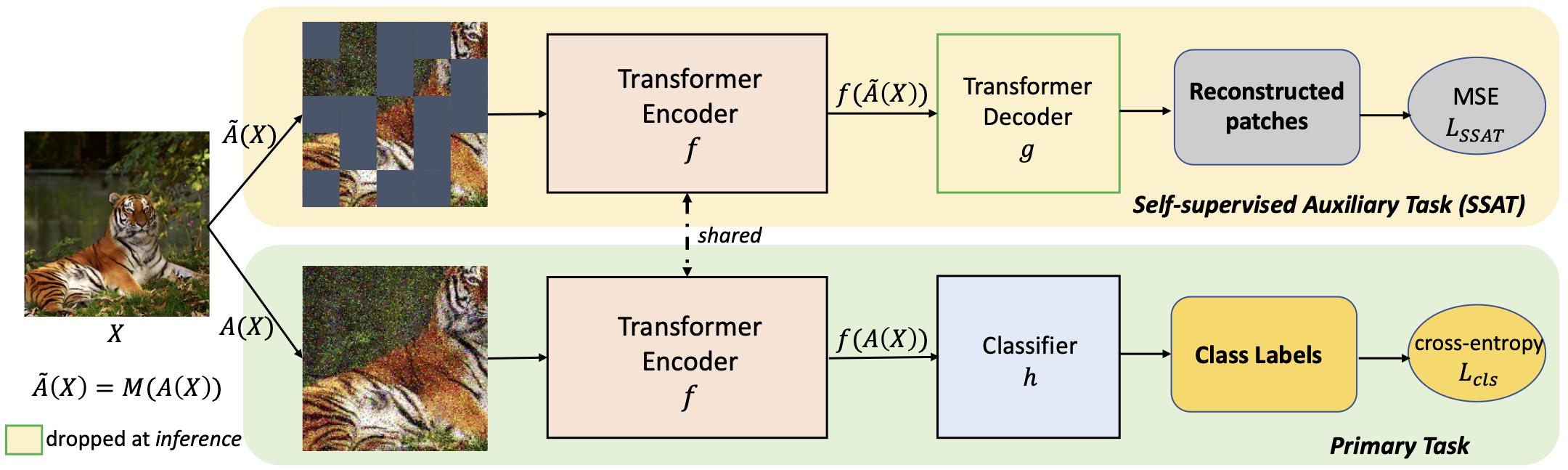
This paper shows that jointly optimizing ViTs for the primary task and a Self-Supervised Auxiliary Task is surprisingly beneficial when the amount of training data is limited.
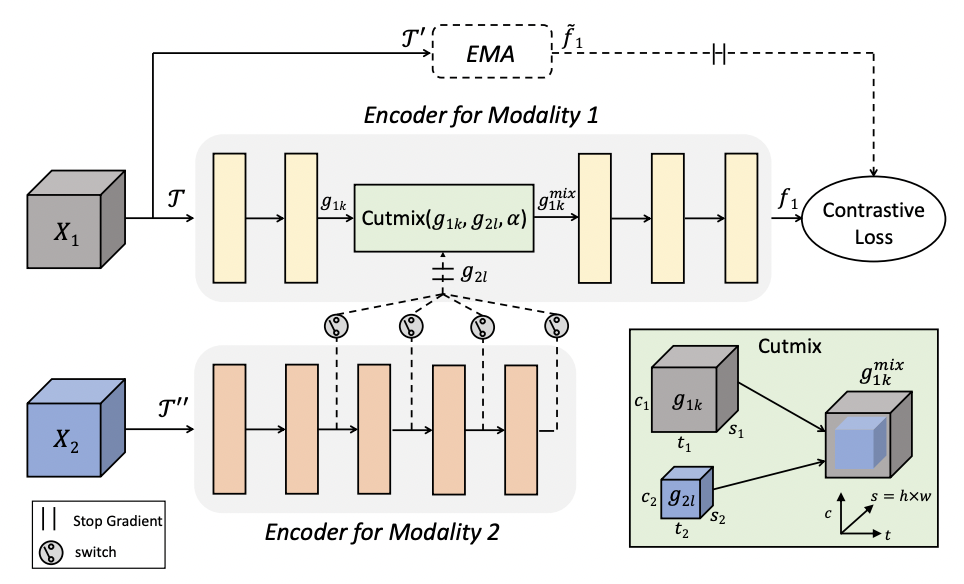
This paper focuses on designing video augmentation for self-supervised learning, we propose CMMC to make use of other modalities in videos for data mixing.
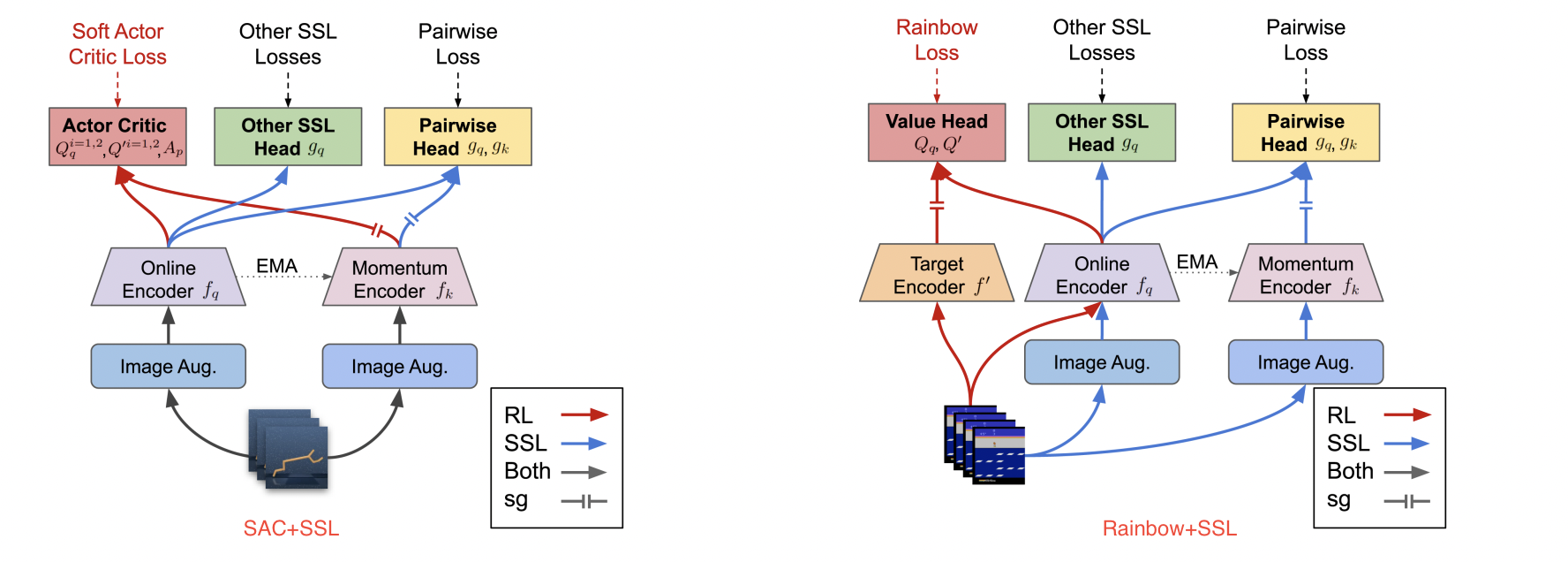
The impacts of the existing self-supervised losses with Joint Learning framework for RL is limited, while there is no golden method that can dominate all tasks.
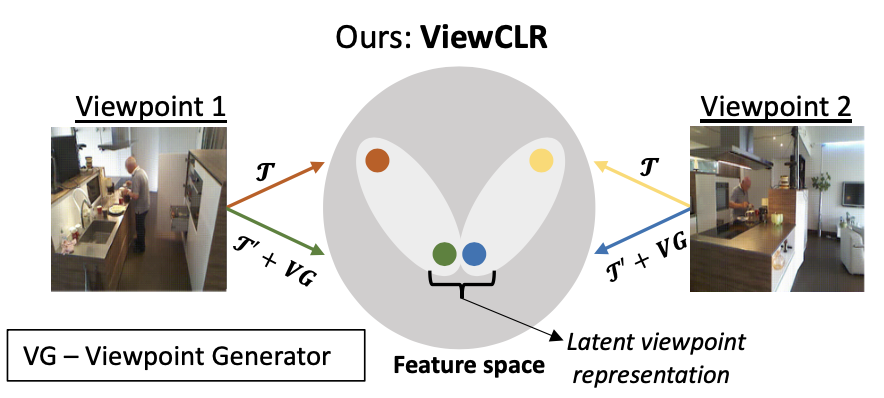
3DTRL is a light-weighted, plug-and play layer that recovers 3D information of visual tokens and leverages it for learning viewpoint-agnostic representations.
May 2025 Invited Talk on "LLAVIDAL: A Large LAnguage VIsion Model for Daily Activities of Living" in the first special WACV 2025 Meetup Series.
May 2025 Invited Academic Talk on "Improved Reasoning in AI Models for Deepfake Detection" in Martigny Biometrics Workshop co-organised by the European Association for Biometrics (EAB), the Center for Identification Technology Research (CITeR) and the Idiap Research Institute at Idiap in Martigny, Switzerland.
May 2025 Invited research poster presentation at the Computing Community Consortium (CCC) Computing Futures Symposium in Washington, DC, USA.
Mar 2025 Guest Lecture on "Deep Neural Networks" at The University of Michigan-Dearborn.
Mar 2024 Talk on "Computer Vision Projects in CharMLab" in a RoundTable discussion on AI in conjunction with the Defense Alliance of NC (DANC) and the Michael Best Law Firm.
Feb 2024 Invited Online Tech Talk on "From Pixels to Robots: Recipes for Vision-Enabled Robot Learning" at Christ University, Bangalore, India.
Dec 2023 Invited Talk on "Video Understanding using AI" as part of the "AI and ROS for Robotics: Theory and Practice" short-term training program at IIITDM.
Jun 2023 Invited Talk on "Computer Vision for Robot Learning" as part of the "AI and Machine Vision for Robotics" short-term training program at IIITDM. (Virtually)
Apr 2023 Talk on "From Few to More: Enhancing ViT Performance on Limited Data" at PHPC Lab in UNC Charlotte.
Mar 2023 Talk on "From Pixels to Robots: Recipes for Vision-Enabled Robot Learning" at the Seminar on Controls and Robotics in UNC Charlotte.
Jan 2023 Talk on "Quo vadis, computer vision!" at the PhD seminar in UNC Charlotte.
Mar 2022 Invited Talk in AICTE sponsored Short Term Course on "Multiple Modalities are all you need for Video Understanding!" at IIITDM Kancheepuram. (Virtually)
Sep 2021 Talk on "Vision for understanding Activities of Daily Living" at SciTech Talks . [video]
Apr 2021 Seminar talk on "How to combine modalities for understanding Activities of Daily Living? " for CSE 600 at Stony Brook University, NY, USA.
Nov 2020 Seminar talk on "How to combine RGB & Poses for understanding Activities of Daily Living?" at Université Lumière Lyon 2.
Serving as Participation & Broadening Chair for WACV 2027.
Program committee member of AAAI-24 Student Program.
Associate Editor for ICRA 2024.
Senior Program Committee Member (Area Chair) for AAAI 2023, AAAI 2024 and AAAI 2026.
Session chair for Image Understanding & Activity Recognition session at IPAS 2020.
Mentored for B.E.N.J.I. in GirlScript Summer of Code 2019 edition.
Mentor for the Emerging Technology Business Incubator (ETBI) Led by NIT Rourkela, a platform envisaged to transform the start-up ecosystem of the region.
Reviewer at TPAMI, IJCV, Pattern Recognition, Elsevier Journal of CVIU, Elsevier Journal of FGCS, Elsevier Journal of Computer & Electrical Engineering, MTAP, and Journal of Signal Processing: Image Communication.










{kind=link}
{kind=link}