|
Preprints
|
|
|
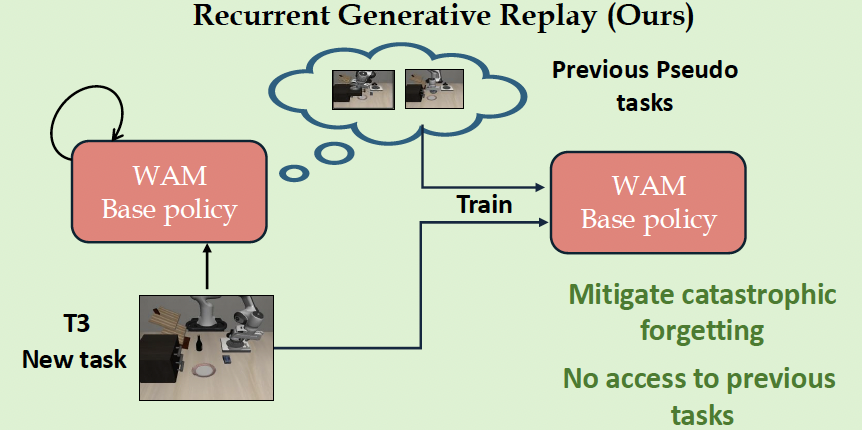
World Action Models Enable Continual Imitation Learning with Generative Replays
Manish Kumar Govind, Dominick Reilly, Hieu Le, Srijan Das.
Preprint
PDF
The first replay-based continual imitation learning framework that leverages the generative capabilities of World Action Models to synthesize replay trajectories without storing real demonstrations from previous tasks.
|
|
|
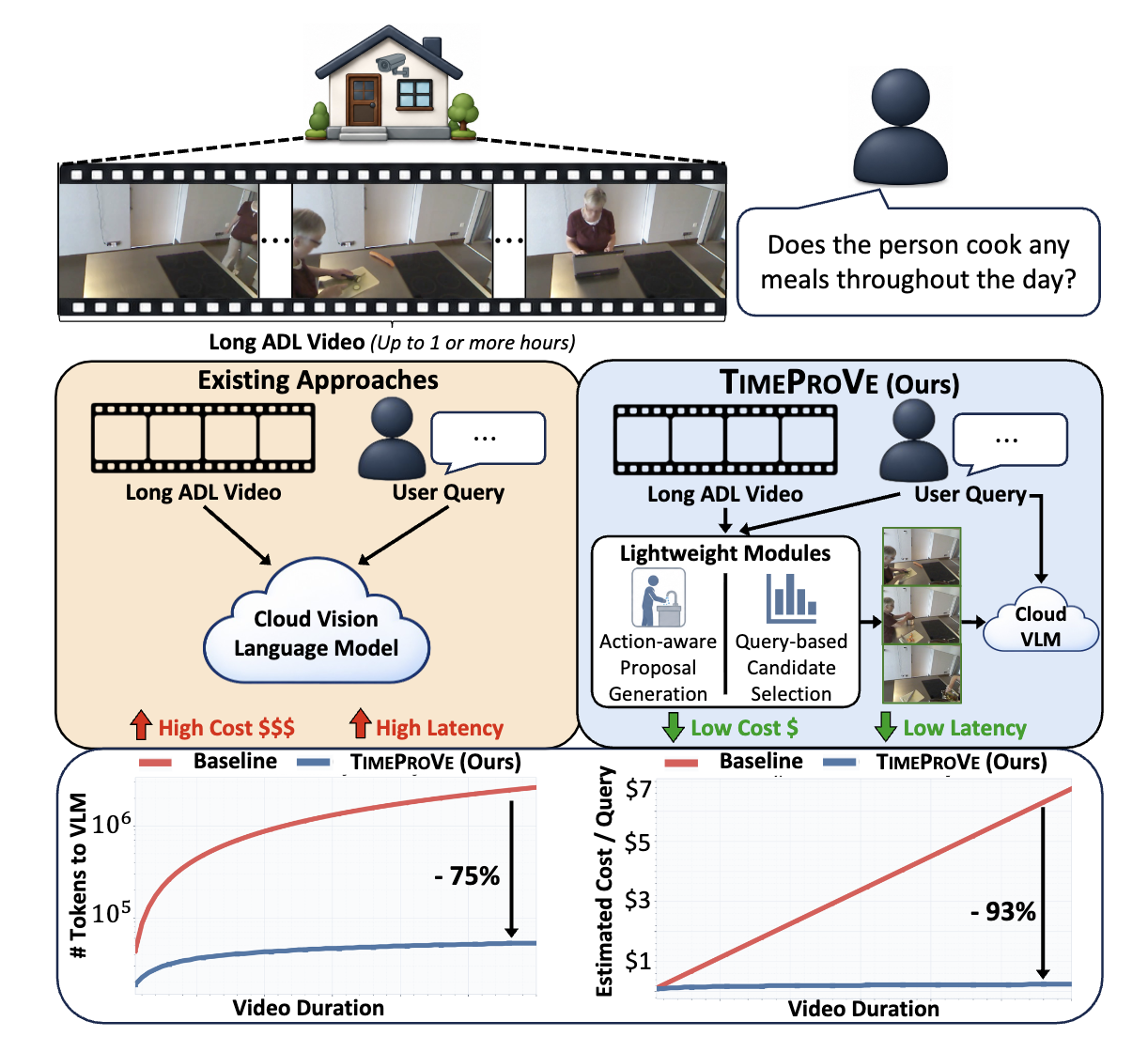
TIMEPROVE: Propose, then Verify for Efficient Long Video Temporal Reasoning in Activities of Daily Living
Arkaprava Sinha, Dominick Reilly, Siddharth Krishnan, Hieu Le, Srijan Das.
Preprint
arXiv
/
website
TIMEPROVE is a hybrid long-video reasoning framework that generates action-grounded hypotheses efficiently and verifies only sparse RGB evidence using an expensive VLM.
|
|
|
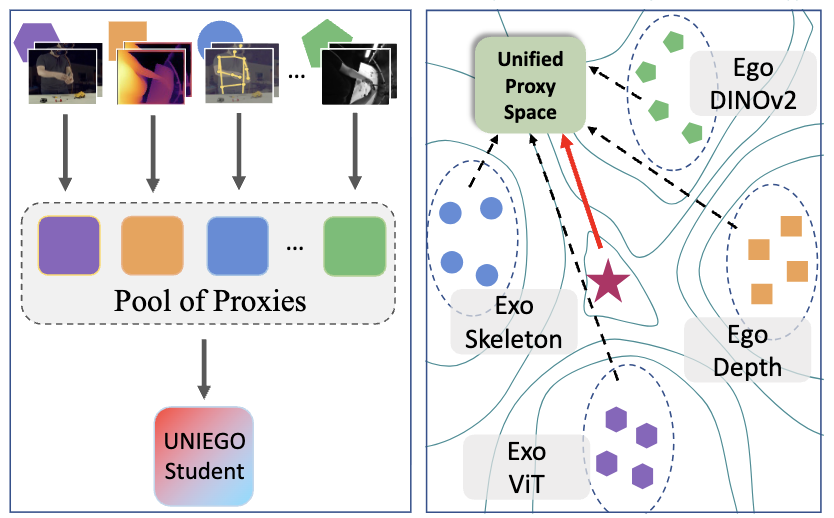
UNIEGO: Proxies as Mediators for Unified Egocentric Video Representation Learning
Wenhao Chi, Arkaprava Sinha, Dominick Reilly, Hieu Le, Srijan Das.
Preprint
arXiv
/
code
UNIEGO is a unified egocentric encoder trained via hierarchical distillation across ego-exo viewpoints, modalities, and foundation models, using representation-specific proxies as structured mediators.
|
|
|
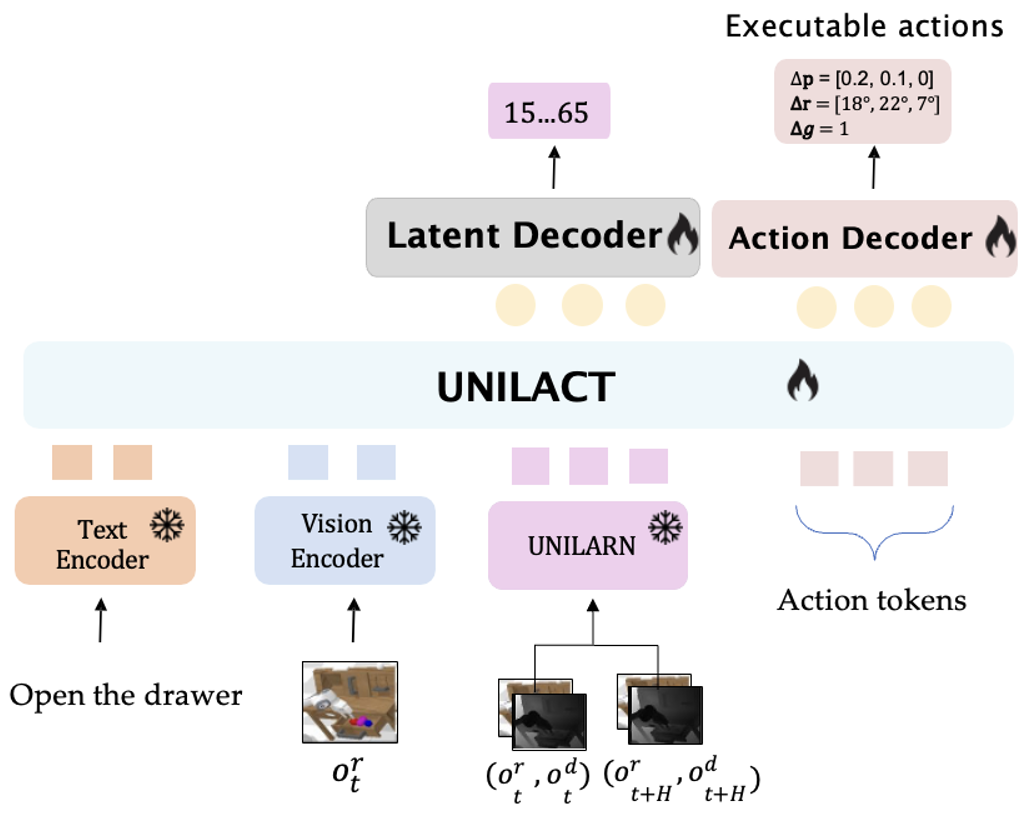
UniLACT: Depth-Aware RGB Latent Action Learning for Vision-Language-Action Models
Manish Kumar Govind, Dominick Reilly, Pu Wang, and Srijan Das.
Preprint
arXiv
/
website
/
Code
UniLACT is a Vision-Language-Action model that incorporates geometric structure through depth-aware latent pretraining, enabling downstream robot policies to inherit stronger spatial priors. |
2026
|
|
|
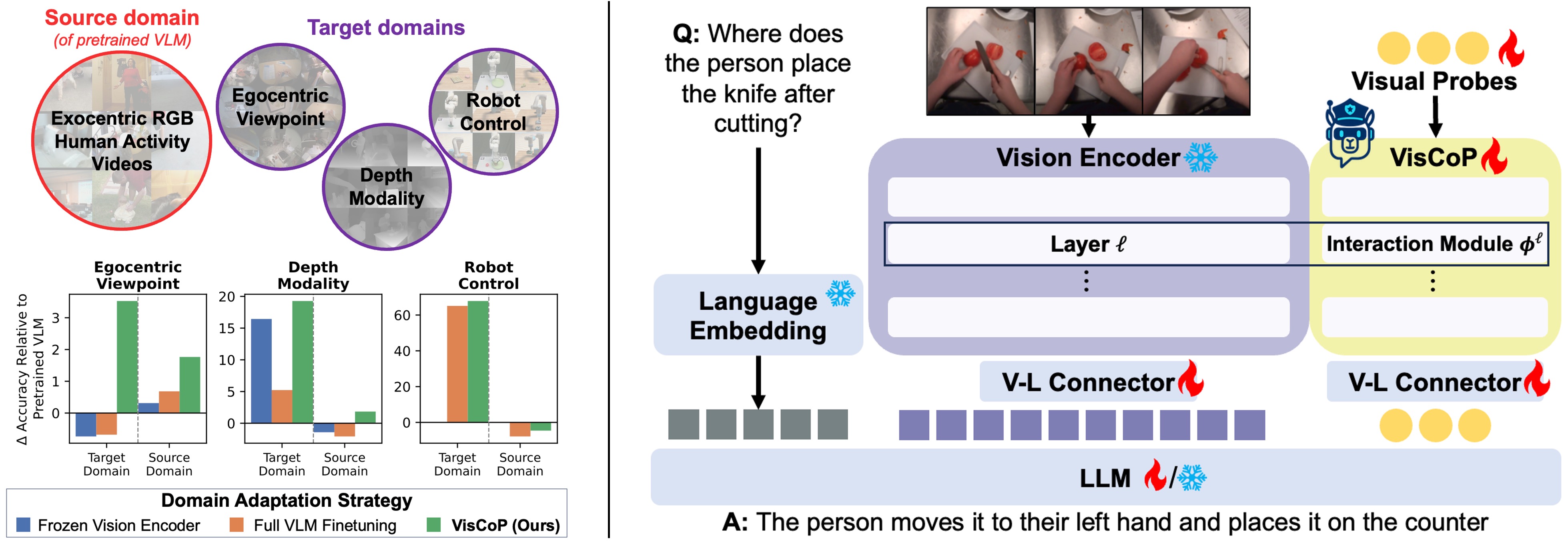
VisCoP: Visual Probing for Domain Adapatation of Vision Language Models
Dominick Reilly, Manish Kumar Govind, Le Xue, and Srijan Das.
To Appear in ECCV 2026
arXiv
/
Code
We introduce Vision Contextualized Probing (VisCoP), which augments the VLM's vision encoder with a compact set of learnable visual probes that enables efficient domain-specific adaptation with minimal modification to pretrained parameters. |
|
|
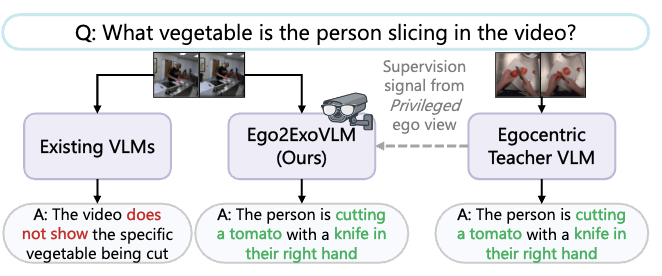
From My View to Yours: Ego-to-Exo Transfer in VLMs for Understanding Activities of Daily Living
Dominick Reilly, Manish Kumar Govind, Le Xue, and Srijan Das.
To Appear in ECCV 2026
arXiv
/
Code
We leverage the complementary nature of egocentric views to enhance LVLM’s understanding of exocentric ADL videos through online ego2exo distillation. |
|
|
MS-Temba : Multi-Scale Temporal Mamba for Efficient Temporal Action Detection
Arkaprava Sinha, Monish Soundar Raj, Pu Wang, Ahmed Helmy, Hieu Le,and Srijan Das.
CVPR 2026
arXiv
/
website
/
code
MS-Temba is the first Mamba based architecture for action detection in long untrimmed videos that can be trained/tested on NVIDIA Jetson Nano.
|
|
|
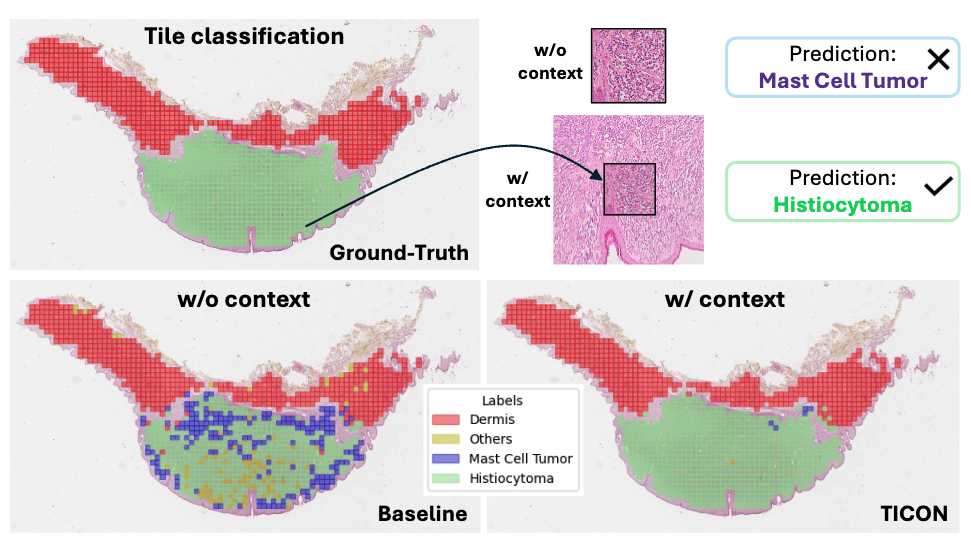
TICON: A Slide-Level Tile Contextualizer for Histopathology Representation Learning
Varun Belagali, Saarthak Kapse, Pierre Marza, Srijan Das, Zilinghan Li, Sofiène Boutaj, Pushpak Pati, Srikar Yellapragada, Tarak Nath Nandi, Ravi K Madduri, Joel Saltz, Prateek Prasanna, Stergios Christodoulidis, Maria Vakalopoulou, Dimitris Samaras.
CVPR 2026 (Findings)
arXiv
/
website
/
code
TICON is an Omni Tile Contextualizer that can contextualize embeddings from any tile encoder.
|
|
|
CORA: Consistency-Guided Semi-Supervised Framework for Reasoning Segmentation
Prantik Howlader, Hoang Nguyen-Canh, Srijan Das, Jingyi Xu, Hieu Le, and Dimitris Samaras.
WACV 2026
arXiv
CORA is a semi-supervised reasoning segmentation framework that jointly learns from limited labeled data and a large corpus of unlabeled images. |
2025
|
|
|
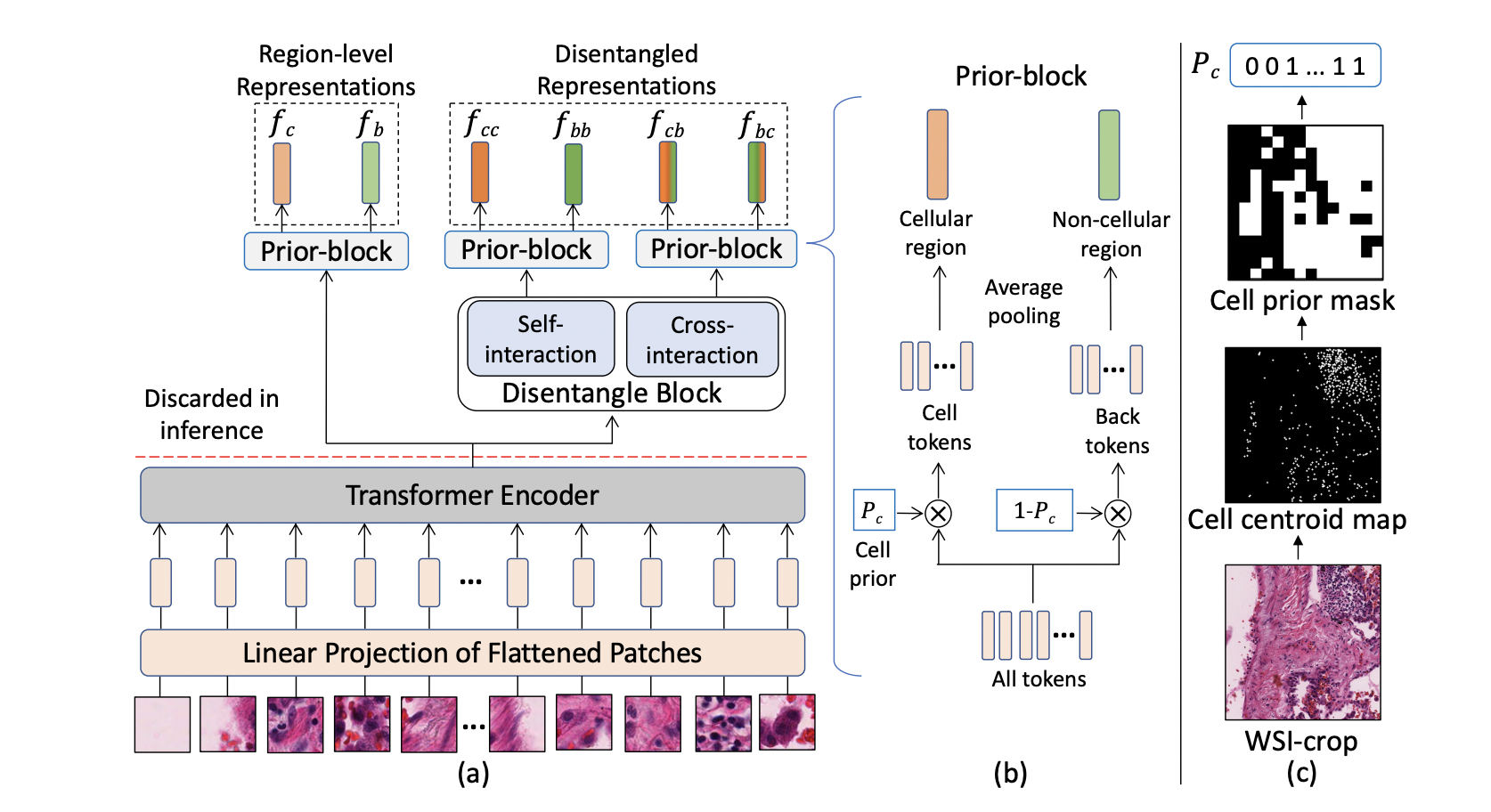
GECKO: Gigapixel Vision-Concept Contrastive Pretraining in Histopathology
Saarthak Kapse, Pushpak Pati, Srikar Yellapragada, Srijan Das , Rajarsi R. Gupta, Joel Saltz, Dimitris Samaras, Prateek Prasanna.
ICCV 2025
arXiv
/
Code
Gigapixel Vision-Concept Knowledge Contrastive pretraining (GECKO) aligns WSIs with a Concept Prior for delivering clinically meaningful interpretability. |
|
|
MaskHand: Generative Masked Modeling for Robust Hand Mesh Reconstruction in the Wild
Muhammad Usama Saleem, Ekkasit Pinyoanuntapong, Mayur Jagdishbhai Patel, Hongfei Xue, Ahmed Helmy, Srijan Das, Pu Wang.
ICCV 2025
arXiv
/
Website
A novel generative masked model for hand mesh recovery that synthesizes plausible 3D hand meshes. |
|
|
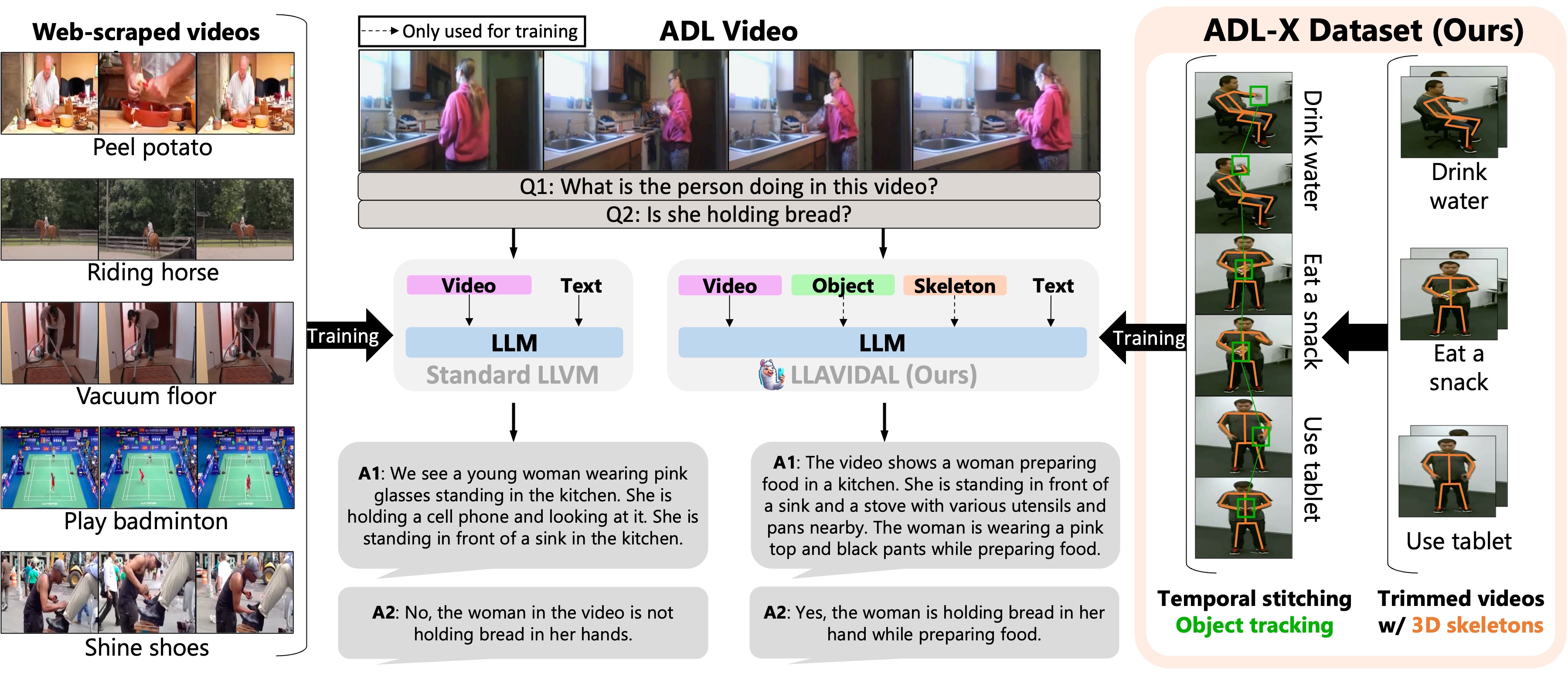
LLAVIDAL : A Large LAnguage VIsion Model for Daily Activities of Living
Dominick Reilly, Rajatsubhra Chakraborty, Arkaprava Sinha, Manish Kumar Govind, Pu Wang, Francois Bremond, Le Xue, Srijan Das.
CVPR 2025
arXiv
/
website
/
code
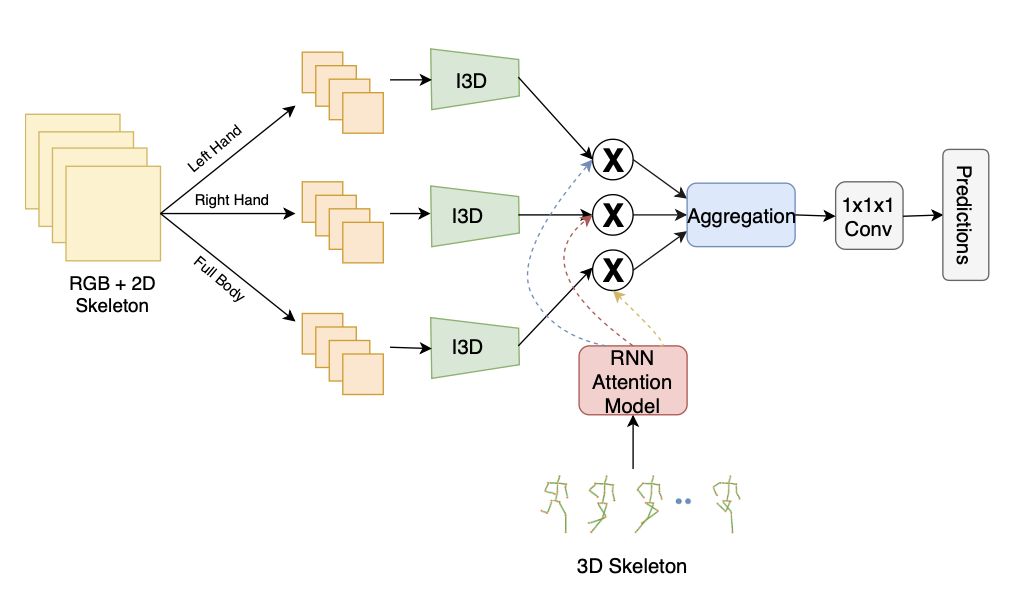
LLAVIDAL, a Large Language Vision Model, incorporates 3D poses and relevant object trajectories to understand the intricate spatiotemporal relationships within ADLs.
|
|
|
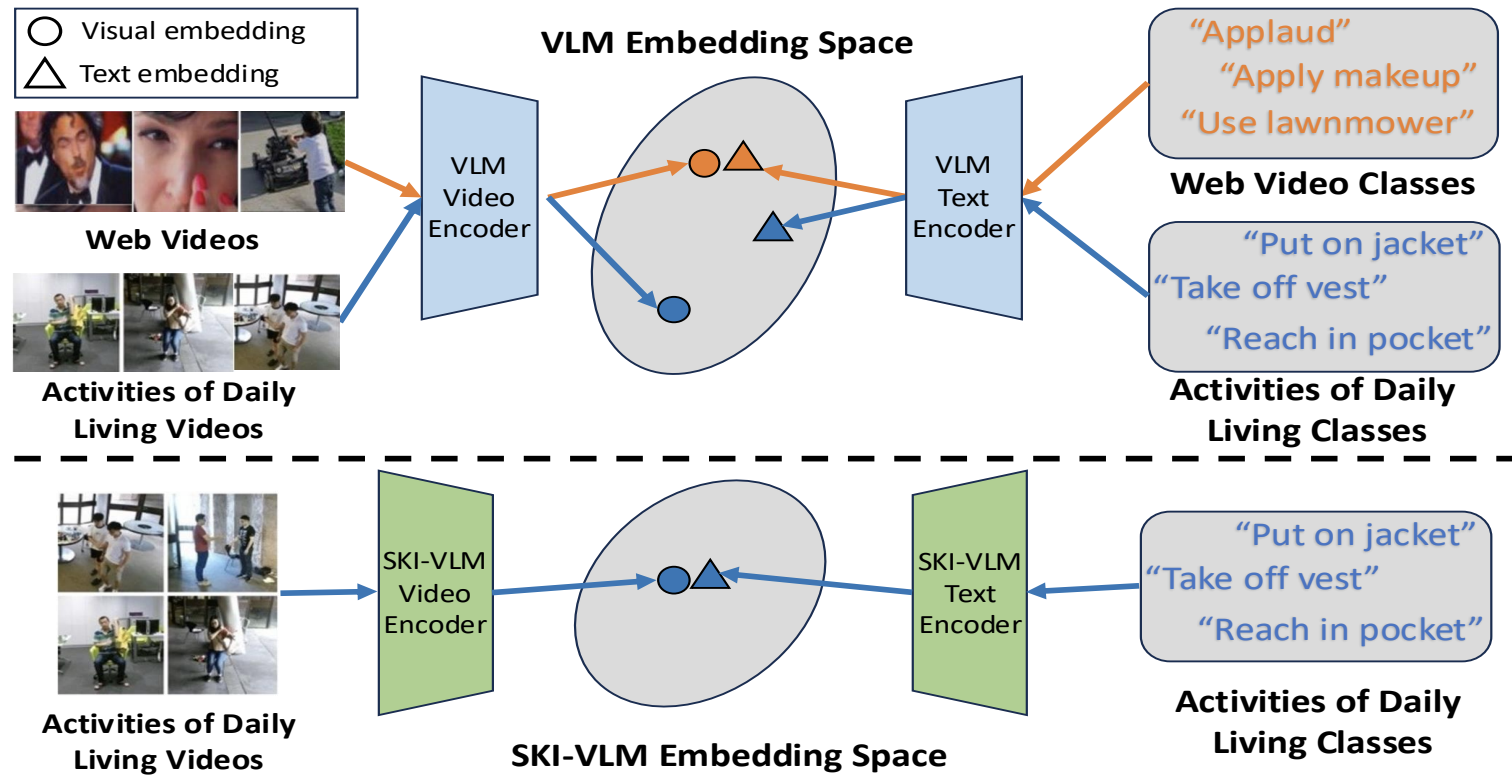
SKI Models: SKeleton Induced Vision-Language Embeddings for Understanding Activities of Daily Living
Arkaprava Sinha, Dominick Reilly, Francois Bremond, Pu Wang, and Srijan Das.
AAAI 2025
arXiv
/
Code
Ski-models introduce 3D skeletons into the vision-language embedding space to enable effective zeroshot learning for ADL. |
|
|
GenHMR: Generative Human Mesh Recovery
Muhammad Usama Saleem , Ekkasit Pinyoanuntapong, Pu Wang, Hongfei Xue, Srijan Das, Chen Chen.
AAAI 2025
arXiv
/
Website
A generative framework that reformulates monocular HMR as an image-conditioned generative task.
|
2024
|
|
|
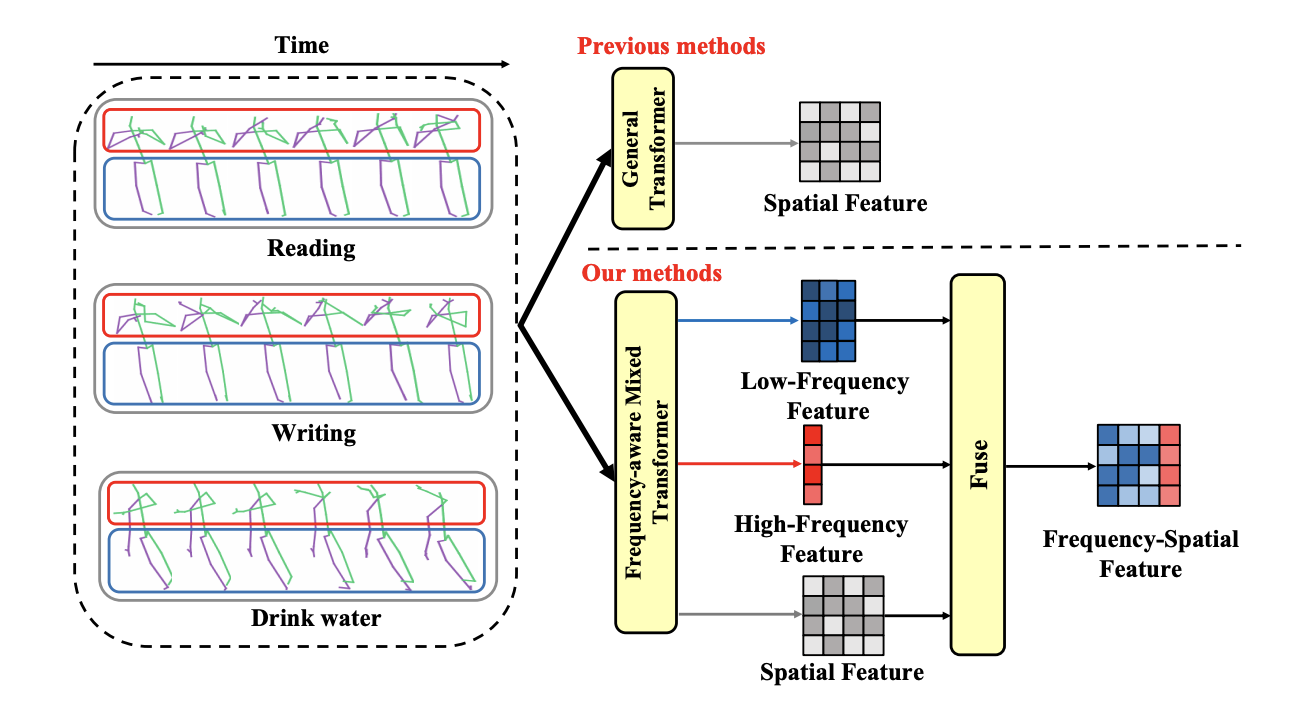
Frequency Guidance Matters: Skeletal Action Recognition by Frequency-Aware Mixed Transformer
Wenhan Wu, Ce Zheng, Zihao Yang, Chen Chen, Srijan Das, Aidong Lu.
ACM MM 2024
arXiv
/
code
A frequency-aware attention module to unweave skeleton frequency representations for action recognition.
|
|
|
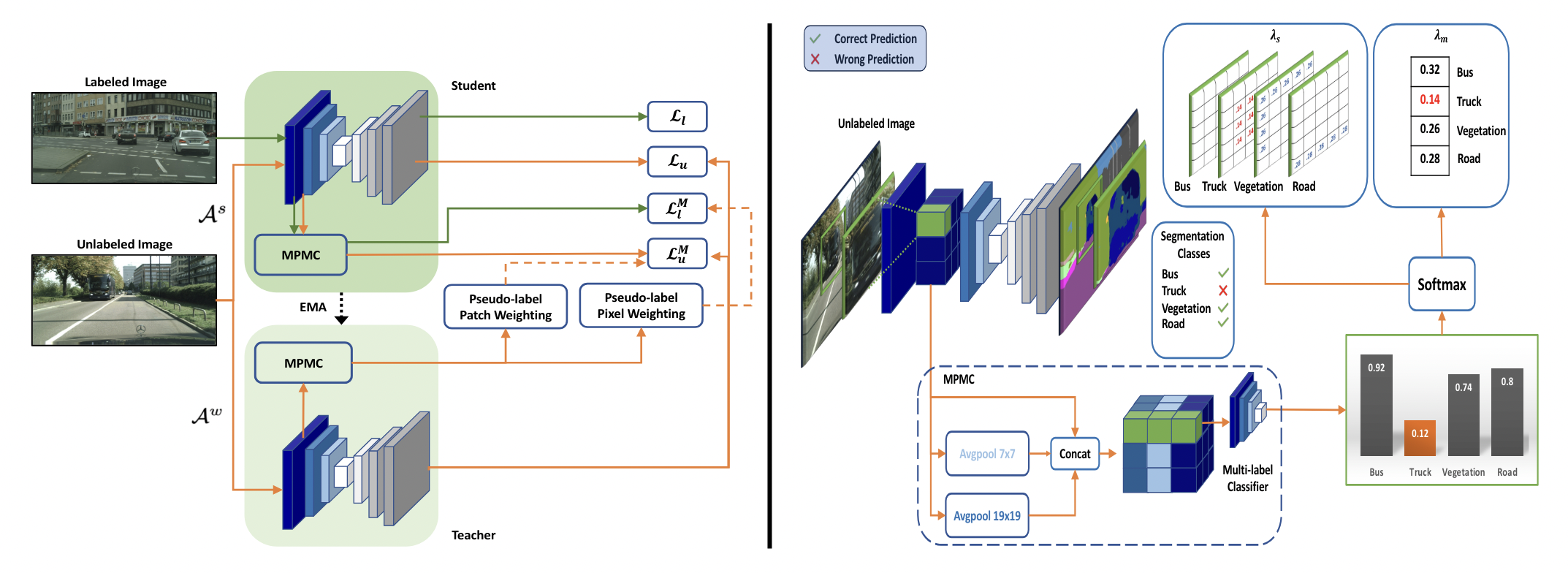
Beyond Pixels: Semi-Supervised Semantic Segmentation with a Multi-scale Patch-based Multi-Label Classifier
Prantik Howlader, Srijan Das, Hieu Le, Dimitris Samaras.
ECCV 2024
arXiv
/
code
A novel plug-in module designed for existing semi-supervised segmentation frameworks that offers patch-level supervision.
|
|
|
BAMM: Bidirectional Autoregressive Motion Model
Ekkasit Pinyoanuntapong, Muhammad Usama Saleem, Pu Wang, Minwoo Lee, Srijan Das, Chen Chen.
ECCV 2024
arXiv
/
website
/
code
A novel text-to-motion generation framework. BAMM captures rich and bidirectional dependencies among motion tokens.
|
|
|
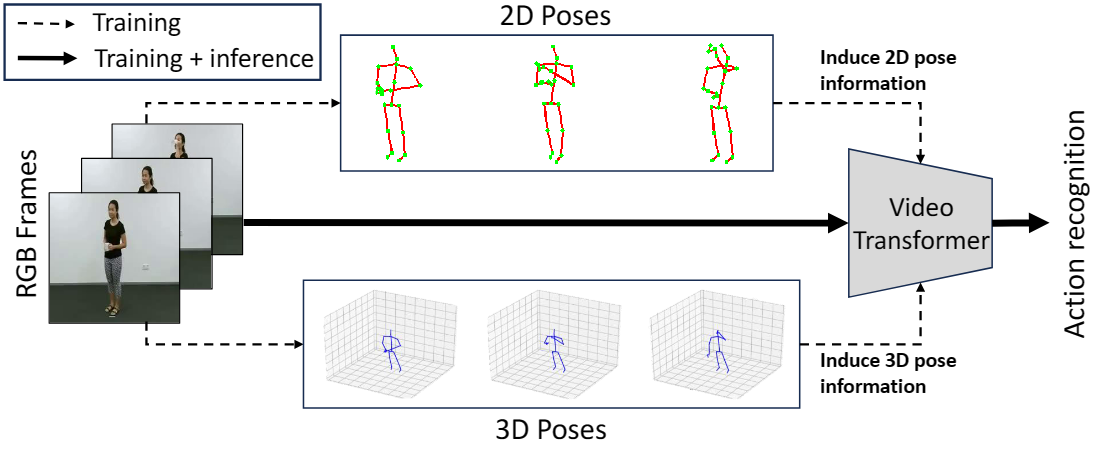
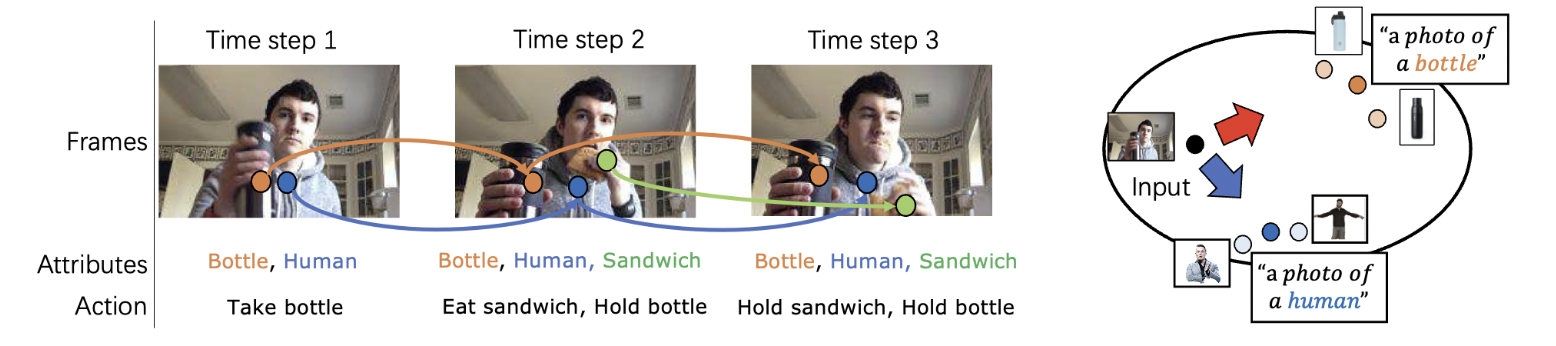
Just Add π! Pose Induced Video Transformers for Understanding Activities of Daily Living
Dominick Reilly and Srijan Das.
CVPR 2024
arXiv
/
code
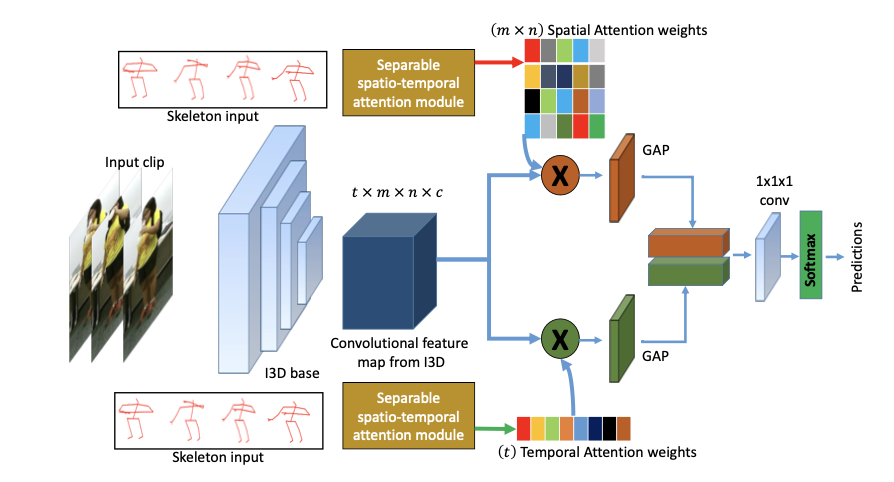
We introduce the first Pose Induced Video Transformer: PI-ViT (or π-ViT), a novel approach that augments the RGB representations learned by video transformers with 2D and 3D pose information.
|
|
|
SI-MIL: Taming Deep MIL for Self-Interpretability in Gigapixel Histopathology
Saarthak Kapse*, Pushpak Pati*, Srijan Das, Jingwei Zhang, Chao Chen, Maria Vakalopoulou, Joel Saltz, Dimitris Samaras, Rajarsi Gupta, Prateek Prasanna.
CVPR 2024
arXiv
/
code
Self-Interpretable MIL (SI-MIL), the first interpretable-by-design MIL method for gigapixel WSIs, which provides de novo feature-level interpretations grounded on pathological insights for a WSI.
|
|
|
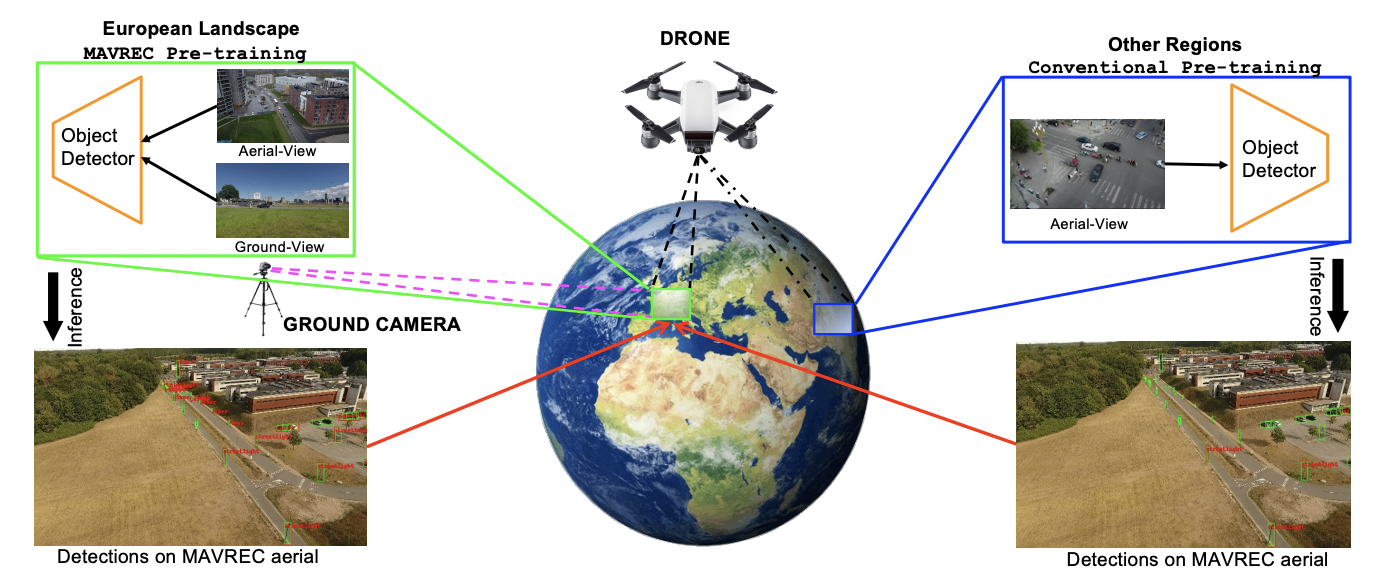
Multiview Aerial Visual Recognition (MAVREC): Can Multi-view Improve Aerial Visual Perception?
Aritra Dutta, Srijan Das , Jacob Nielsen, Rajatsubhra Chakraborty, Mubarak Shah.
CVPR 2024
arXiv
/
Website
We present MAVREC, a video dataset where we record synchronized scenes from different perspectives -- ground camera and drone-mounted camera.
|
|
|
Attention de-sparsification Matters: Inducing Diversity in Digital Pathology Representation Learning
Saarthak Kapse, Srijan Das, Jingwei Zhang, Rajarsi R. Gupta, Joel Saltz, Dimitris Samaras, Prateek Prasanna.
Medical Image Analysis (IF 10.9)
arXiv
A diversity-inducing pretraining technique, tailored to enhance representation learning in digital pathology.
|
|
|
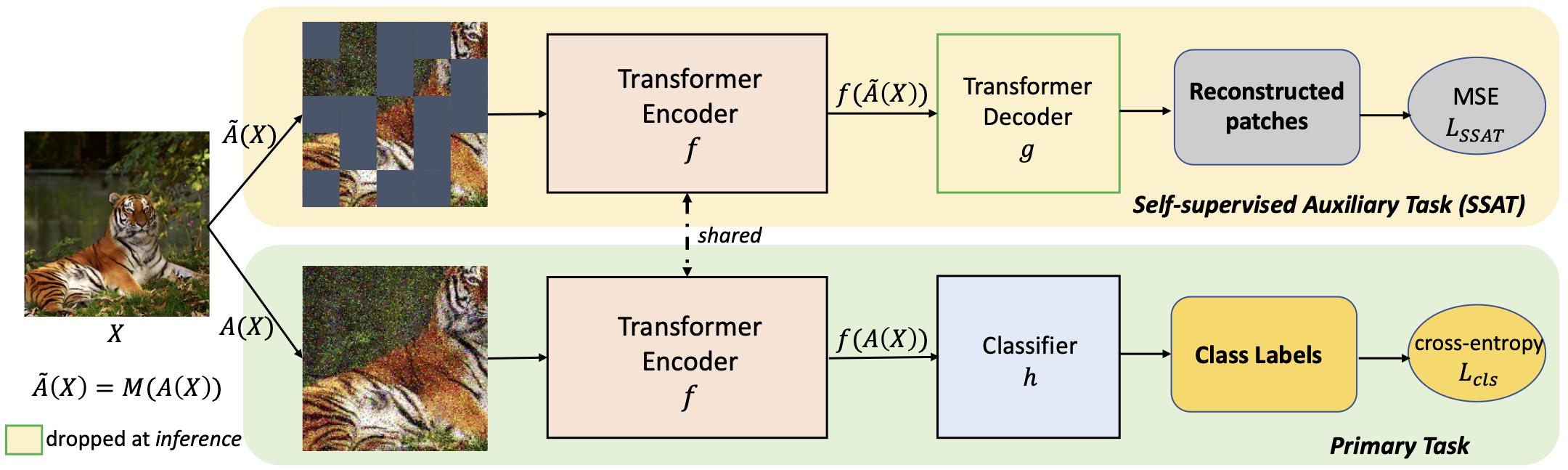
Limited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders
Srijan Das, Tanmay Jain, Dominick Reilly, Pranav Balaji, Soumyajit Karmakar, Shyam Marjit, Xiang Li, Abhijit Das, and Michael S. Ryoo.
WACV 2024
arXiv
/
code
/
Poster
/
Video
This paper shows that jointly optimizing ViTs for the primary task and a Self-Supervised Auxiliary Task is surprisingly beneficial when the amount of training data is limited.
|
2023
|
|
|
Attributes-Aware Network for Temporal Action Detection
Rui Dai, Srijan Das, Michael S. Ryoo, Francois Bremond.
BMVC 2023
arXiv / video
This paper explains how to utilize OpenAI's CLIP for long-term action detection in videos.
|
|
|
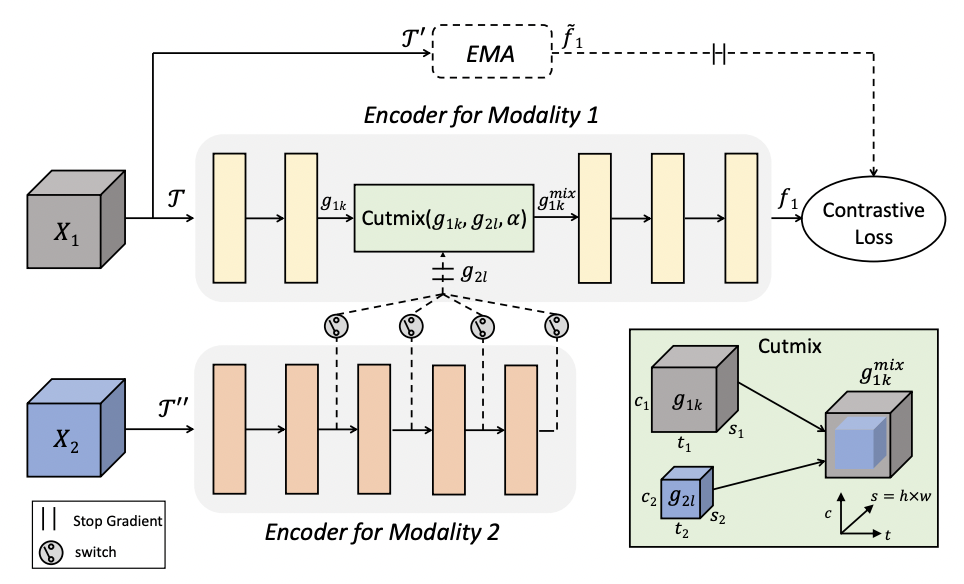
Cross-modal Manifold Cutmix for Self-supervised Video Representation Learning
Srijan Das and Michael S. Ryoo.
18th International Conference on Machine Vision Applications , July 2023
arXiv
/
Poster
/
Best Poster Award
This paper focuses on designing video augmentation for self-supervised learning, we propose CMMC to make use of other modalities in videos for data mixing.
|
|
|
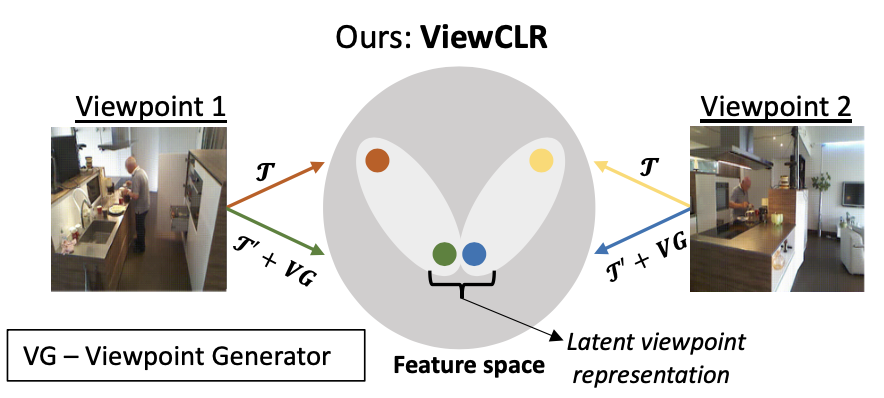
ViewCLR: Learning Self-supervised Video Representation for Unseen Viewpoints
Srijan Das, and Michael S. Ryoo.
WACV 2023
arXiv
A framework for learning self-supervised video representation that is invariant to unseen camera viewpoints.
|
2022
|
|
|
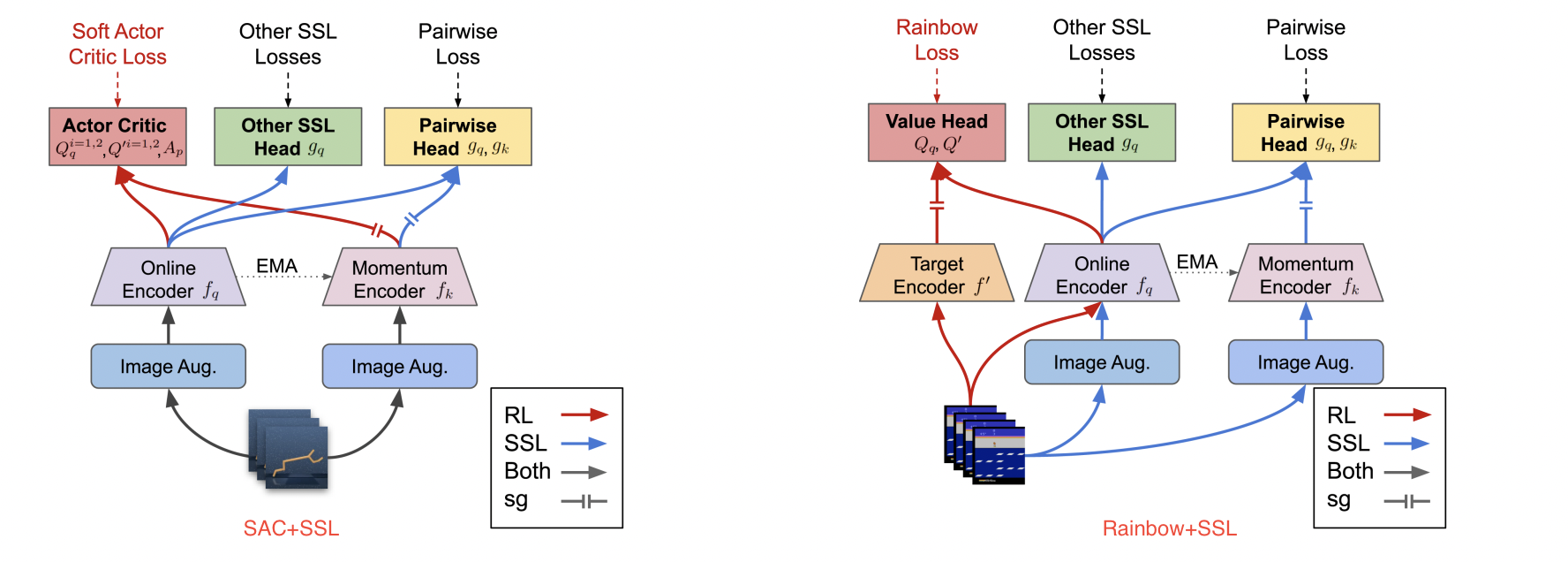
Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?
Xiang Li, Jinghuan Shang, Srijan Das, Michael S. Ryoo.
NeurIPS 2022
arXiv
/
code
The impacts of the existing self-supervised losses with Joint Learning framework for RL is limited, while there is no golden method that can dominate all tasks.
|
|
|
Learning Viewpoint-Agnostic Visual Representations by Recovering Tokens in 3D Space
Jinghuan Shang, Srijan Das, Michael S. Ryoo.
NeurIPS 2022
arXiv
/
Project Page
/
code
3DTRL is a light-weighted, plug-and play layer that recovers 3D information of visual tokens and leverages it for learning viewpoint-agnostic representations.
|
|
|
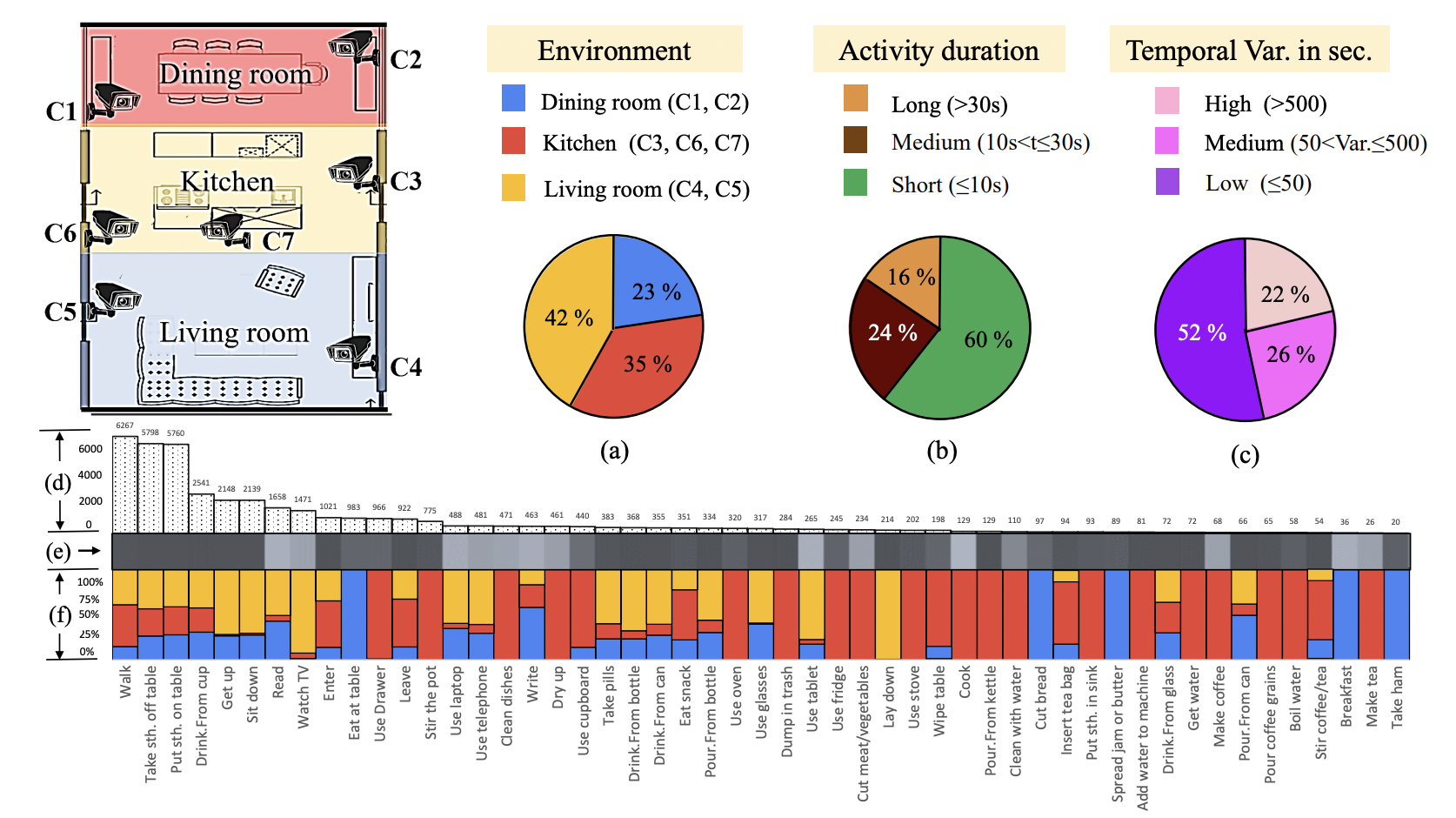
Toyota Smarthome Untrimmed: Real-World Untrimmed Videos for Activity Detection
Rui Dai, Srijan Das, Saurav Sharma, Luca Minciullo, Lorenzo Garattoni, François Brémond, Gianpiero Francesca.
T-PAMI 2022
Project Link / Code
TSU is a new untrimmed daily-living dataset consisting of 51 activities performed in a spontaneous manner, captured from non-optimal viewpoints.
|
|
|
MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection
Rui Dai, Srijan Das, Kumara Kahatapitiya, Michael S. Ryoo, Francois Bremond.
CVPR 2022
arXiv
/
code
A ConvTransformer network that explores global and local temporal relations at multiple resolutions.
|
2021
|
|
|
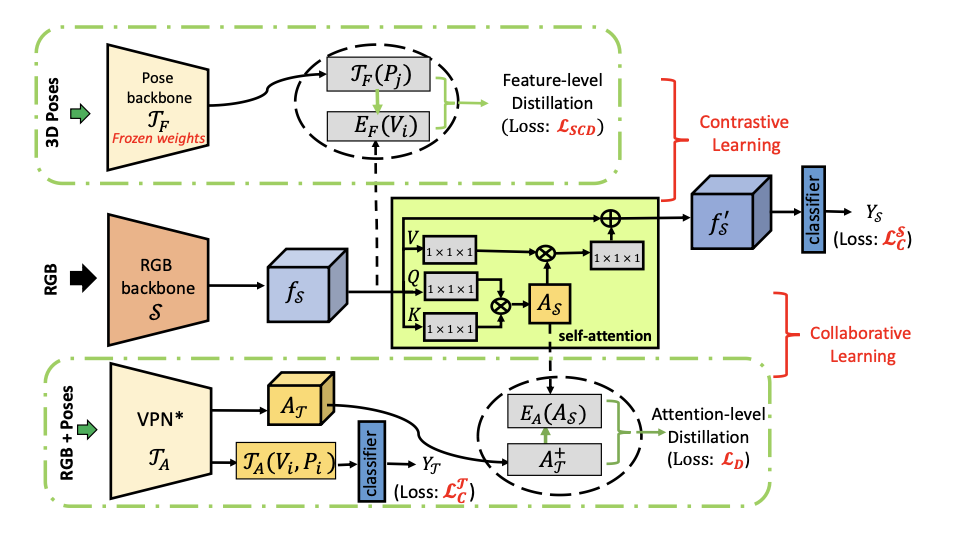
VPN++: Rethinking Video-Pose embeddings for understanding Activities of Daily Living
Srijan Das, Rui Dai, Di Yang, Francois Bremond,
TPAMI, 2021
arXiv
/
code
VPN++ is an extension of our VPN model (ECCV 2020). VPN++ hallucinates pose driven features while not requiring costly 3D Poses at inference.
|
|
|
CTRN: Class Temporal Relational Network for Action Detection
Rui Dai, Srijan Das, Francois Bremond.
BMVC 2021, Oral
|
|
|
Learning an Augmented RGB Representation with Cross-Modal Knowledge Distillation for Action Detection
Rui Dai, Srijan Das, Francois Bremond.
ICCV 2021
|
|
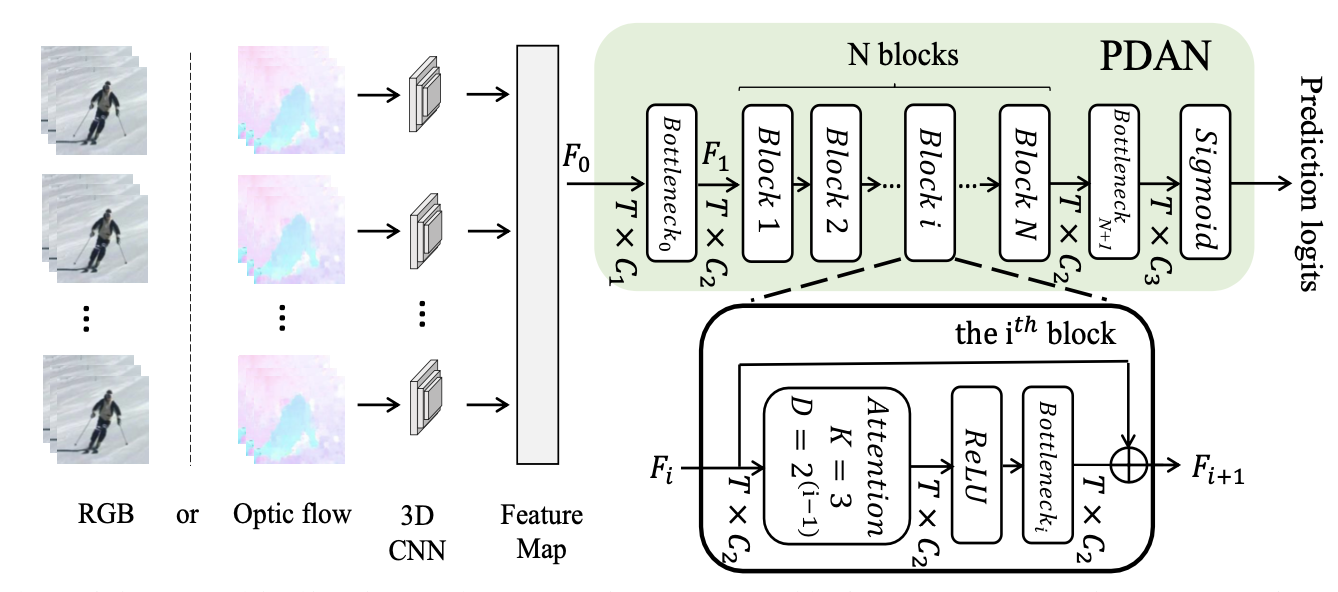
PDAN: Pyramid Dilated Attention Network for Action Detection.
Rui Dai, Srijan Das, Luca Minciullo, Lorenzo Garattoni, Gianpiero Francesca and Francois Bremond.
WACV 2021
Code / Video / Poster
|
2020
|
|
|
VPN: Learning Video-Pose Embedding for Activities of Daily Living
Srijan Das, Saurav Sharma, Rui Dai, Francois Bremond, Monique Thonnat.
ECCV 2020
Code
|
|
|
Looking deeper into Time for Activities of Daily Living Recognition
Srijan Das, Monique Tonnat and Francois Bremond.
WACV 2020
|
2019
|
|
|
Toyota Smarthome: Real World Activities of Daily Living.
Srijan Das, Rui Dai, Michal Koperski, Luca Minciullo, Lorenzo Garattoni, Francois Bremond and Gianpiero Francesca.
ICCV 2019
Project Link / Code
|
|
|
Where to focus on for Human Action Recognition?
Srijan Das, Arpit Chaudhary, Francois Bremond and Monique Thonnat.
WACV 2019
|










{kind=link}
{kind=link}